第四章:数据导入和导出
作者:陈希章,2023年1月 于上海 专栏:大数据分析新玩法之Kusto宝典 第一季:一元初始 反馈:ares@xizhang.com
在前面的章节中,我们使用 https://help.kusto.windows.net 这个范例群集,以及主要使用了它内部的 Samples 这个数据库进行查询和分析。
那么,现在是时候来创建自己的群集,数据库,并且按照自己的需要来导入和导出数据了,只有完成了这一步,你才能较为全面地掌握Kusto(或者叫Azure Data Explorer)的能力。
如果你希望在生产环境使用 ADE, 你需要有Microsoft Azure的订阅,然后通过 https://portal.azure.com/#create/Microsoft.AzureKusto 来创建,它的收费方式,请参考 https://azure.microsoft.com/en-us/pricing/details/data-explorer/ 的详情。
但是,如果你只是用来研究和学习,则完全可以从免费的群集开始。
创建免费群集
为了创建免费群集,你可以访问 https://aka.ms/kustofree 或者 https://dataexplorer.azure.com/freecluster。
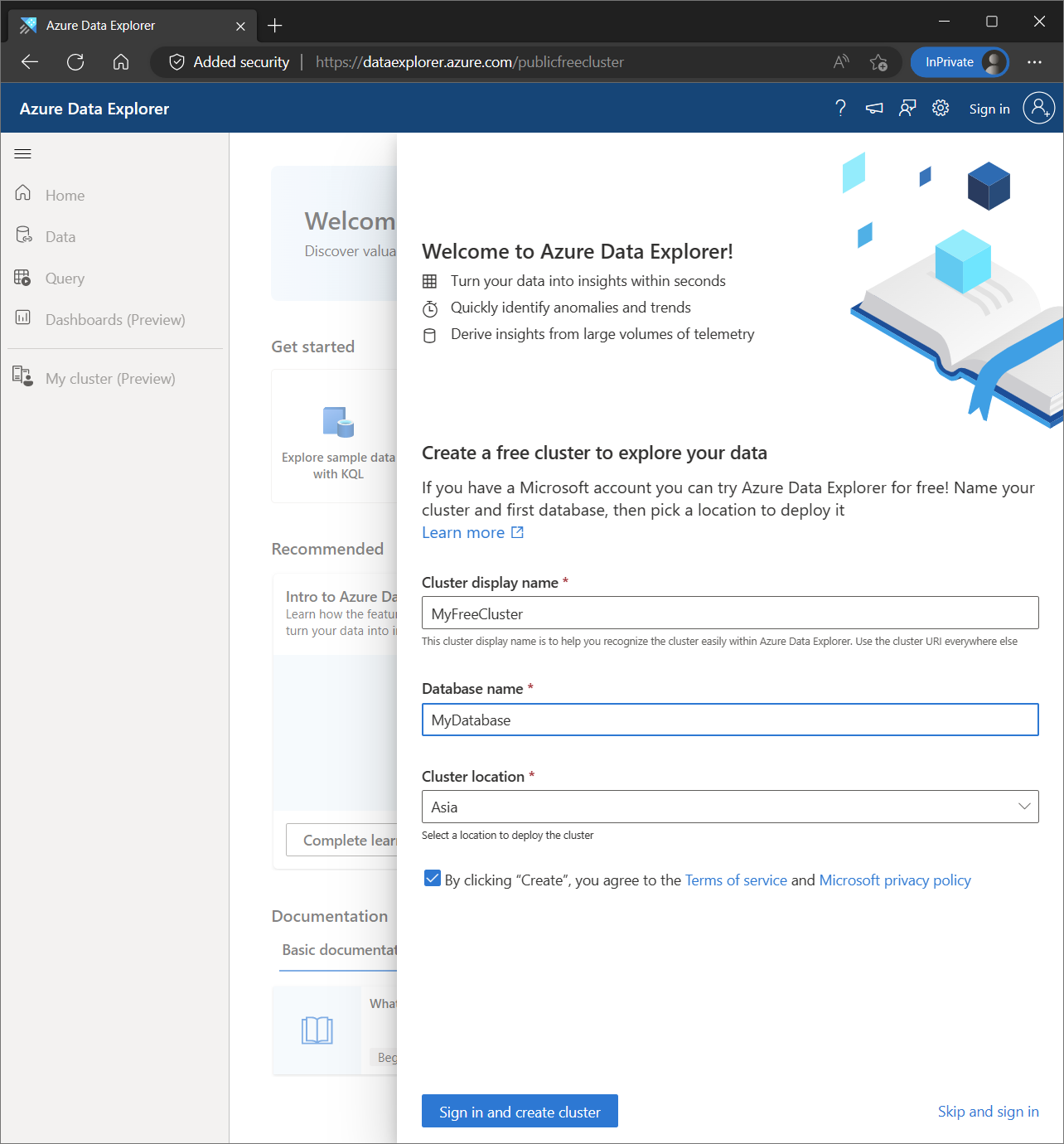
输入你想要的群集显示名称,数据库名称和位置,然后完成登录操作后,你就可以拥有自己专属的群集了。你可以用 Microsoft 个人账号,或者工作账号登录。
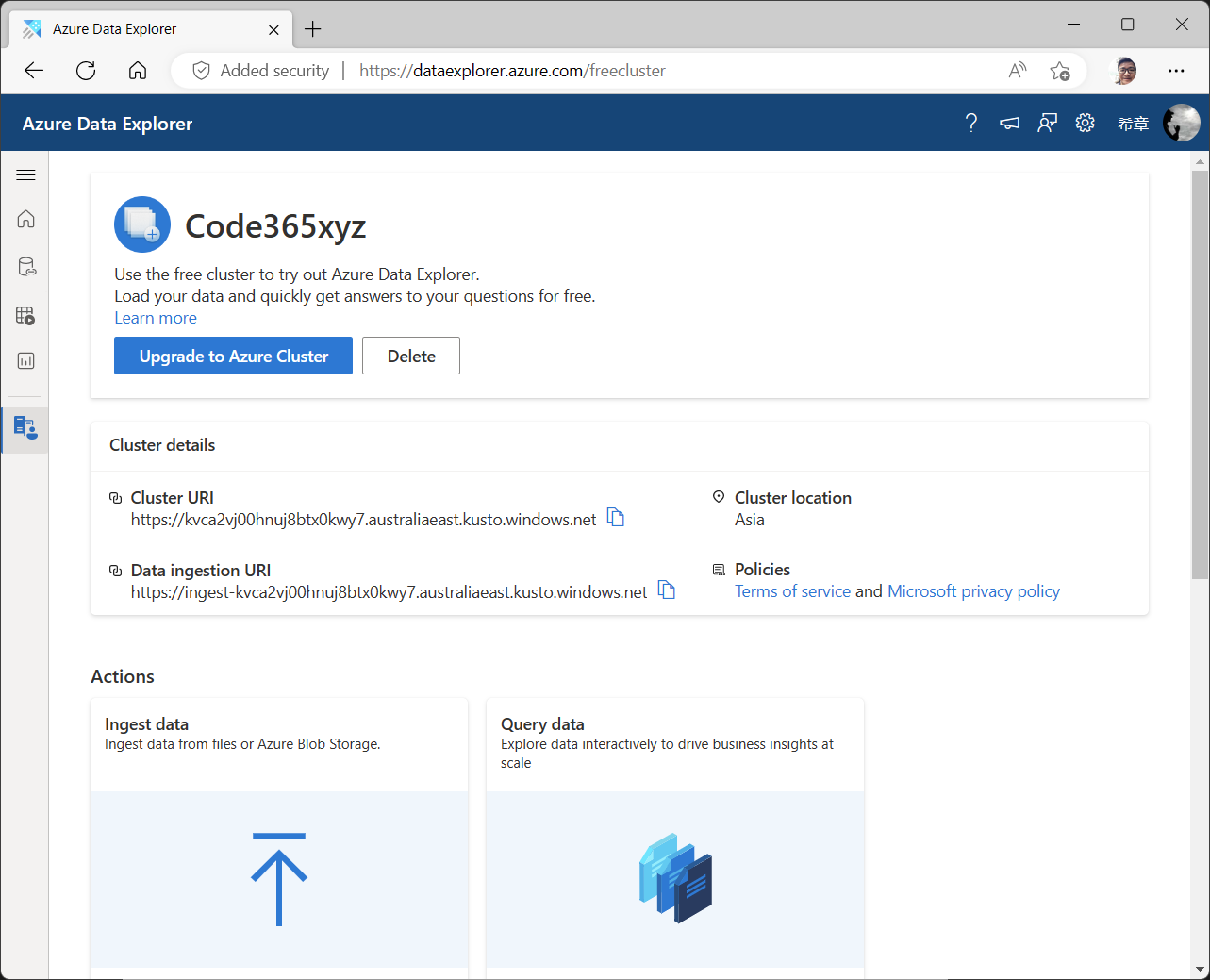
每个群集都会有一个唯一的地址,作为免费群集,你不可以修改这个地址。而即便是免费版本,你也拥有了相当不错的配置。

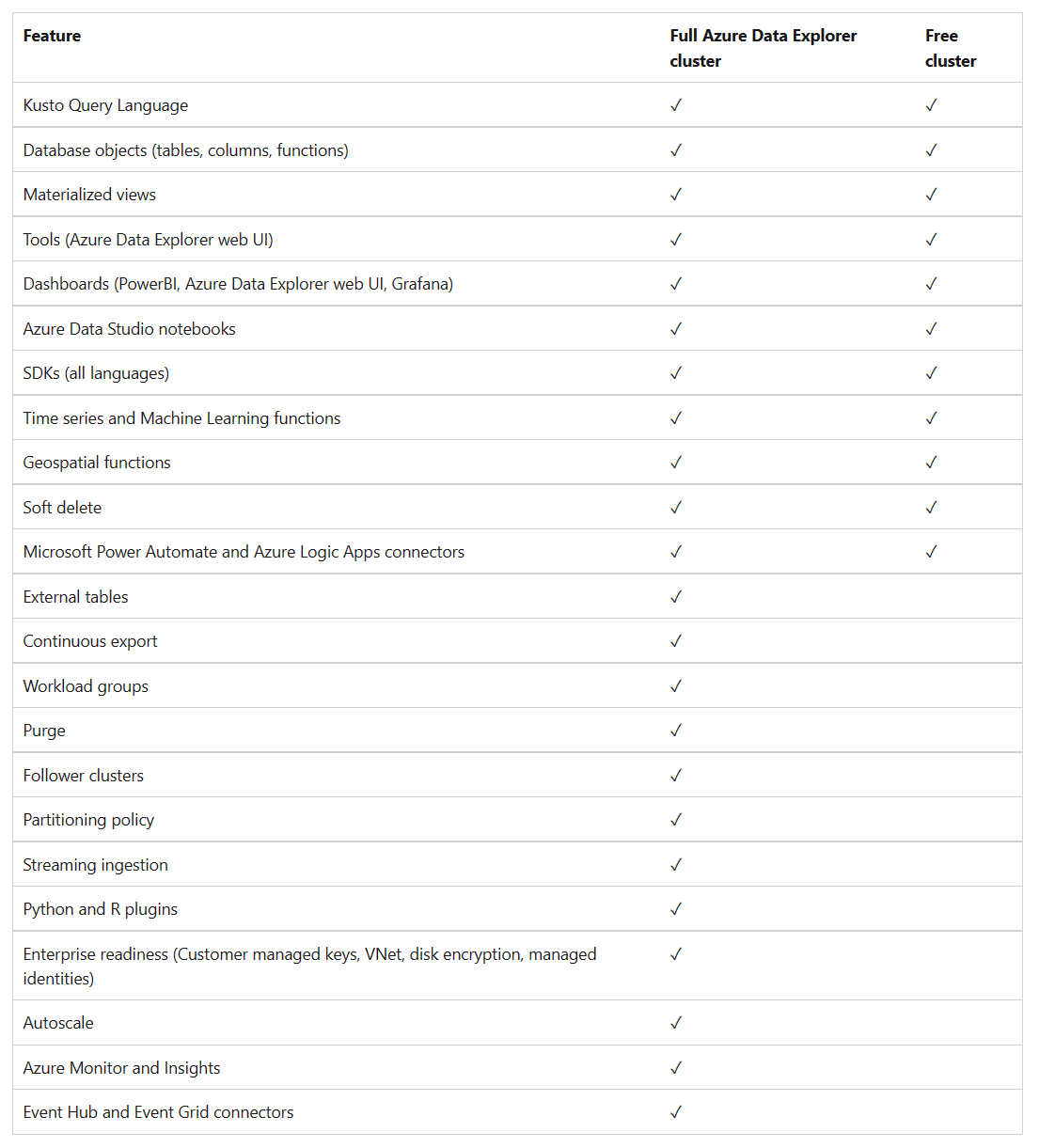
当然,它跟正式版肯定会有所差异,请通过下表了解。
创建数据库
正如你所看到的,免费群集中允许最多10个数据库。创建数据库是很简单的,你还是可以通过 https://aka.ms/kustofree 进入控制面板,然后点击 ”Create database “ 即可。
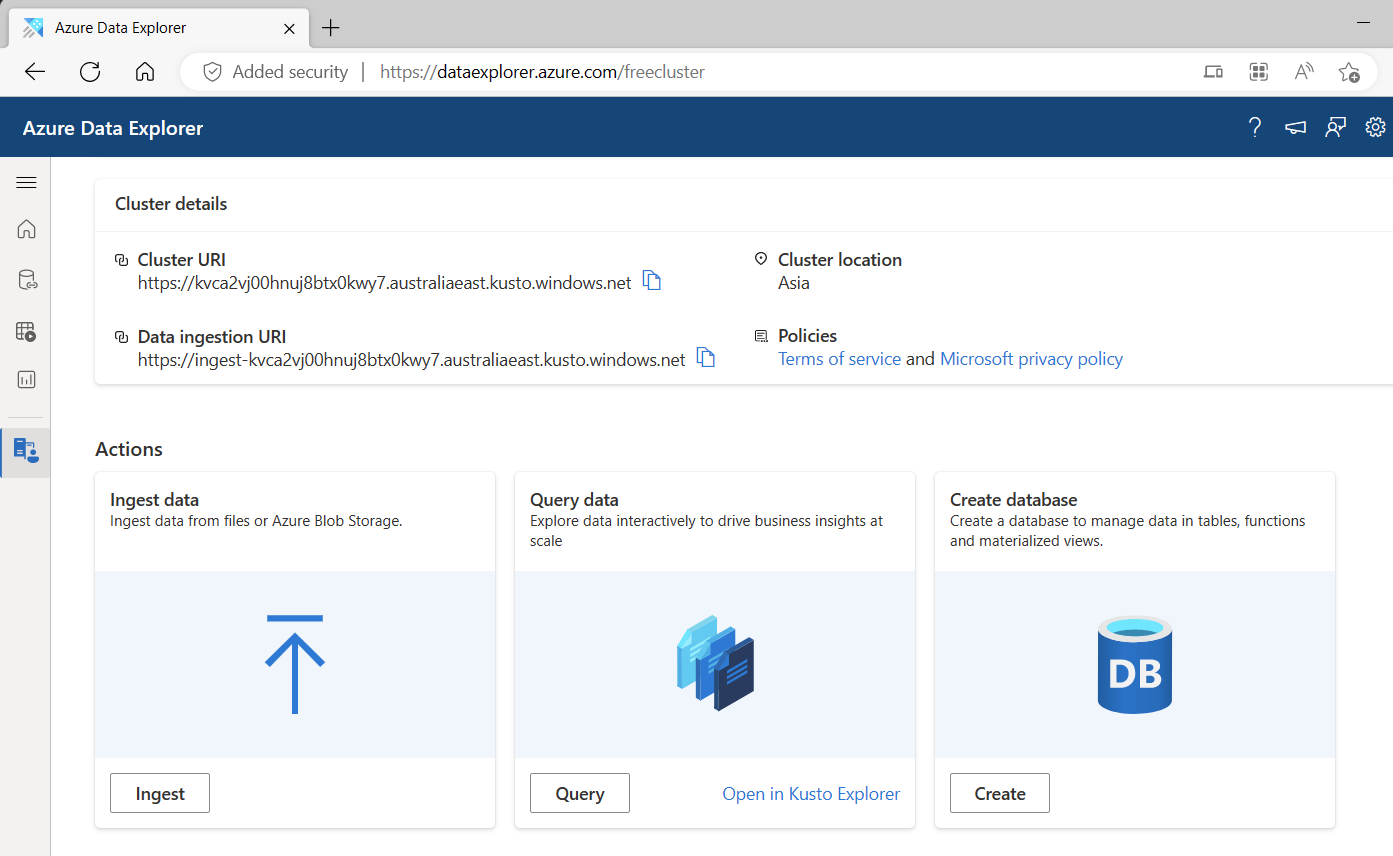
为了便于一起做练习,请确保你创建了一个数据库叫 ”Kusto2023“。
导入数据
有了群集和数据库,接下来就是导入你自己需要的数据了。你可以通过多种方式进行导入,下面我们一一介绍。
从本地数据中导入
这是初学者最常见的一种方式,谁还没有一点数据在本地计算机呢?虽然Kusto支持很多不同的格式,但用的最多的还是文本文件,而且具体来说就是 csv 文件和 tsv 文件,当然也可以是 json 文件。
csv和tsv都是用分隔符隔断的文本文件,区别在于csv用的是逗号(,),而tsv用的是Tab键。- 我个人更喜欢用
csv,但是tsv在某些时候也有奇效,尤其是你的数据字段中包含引号,逗号,空格等字符时。 json格式会给导入带来不必要的麻烦,除非必要,尽量少用。
假设现在我们已经有了一个 csv 文件,为了简单起见,我用如下的 Powershell 命令生成了当前我的电脑运行的程序的清单。
gps | Export-Csv gps.csv
你可能会经常用到 Export-Csv 这个命令,请参考它的详细说明 https://learn.microsoft.com/en-us/powershell/module/microsoft.powershell.utility/export-csv , 如果是导出
tsv,则这个命令是gps | Export-Csv gps.tsv -Delimitert`
这个文件看起来是下面这样的
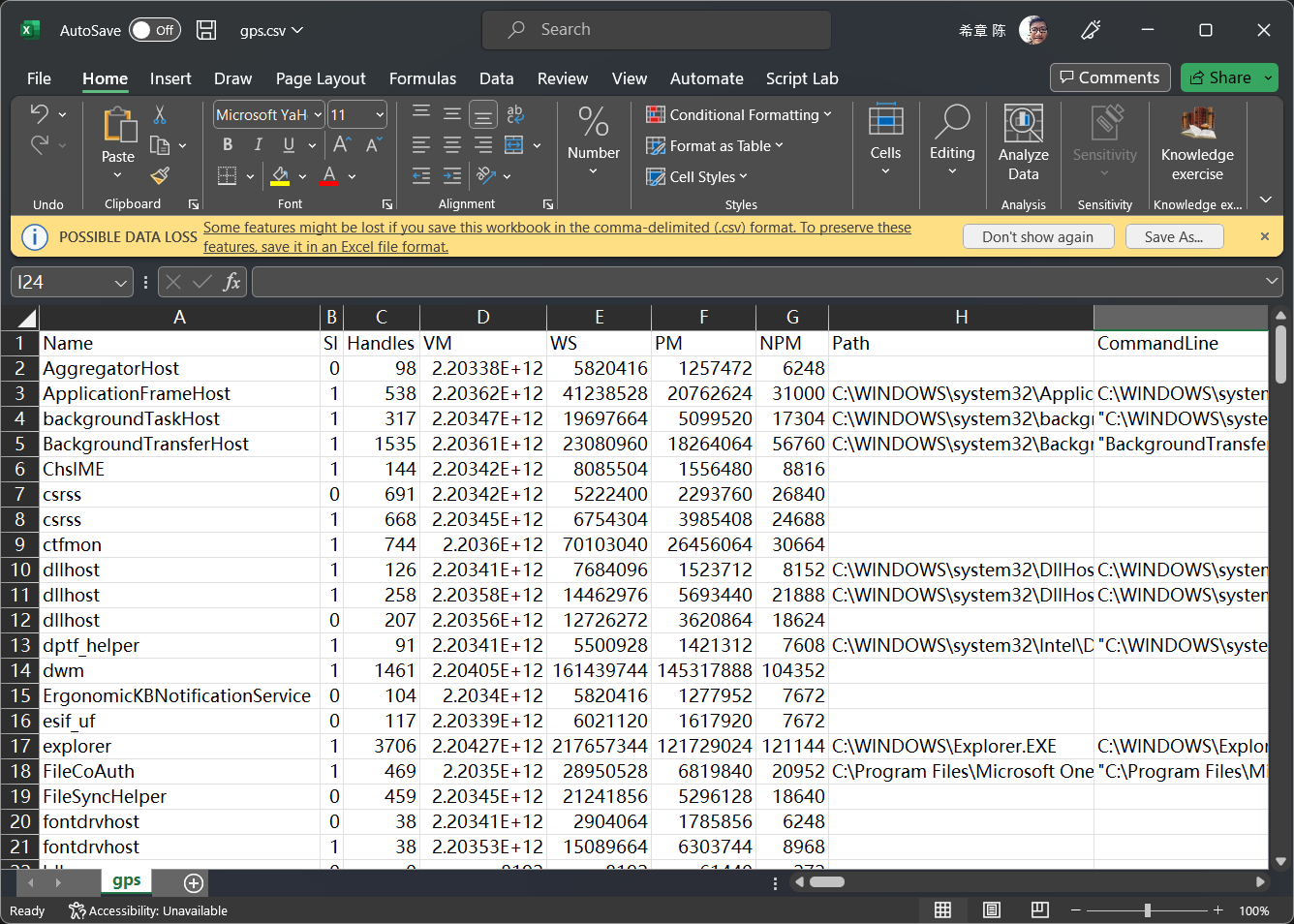
那么接下来我们就看一下如何将这个文件导入到 Kusto2023 这个数据库吧。你可以通过访问 https://aka.ms/kustofree 进入免费群集的首页。
点击 ”Ignest“ 这个 按钮,进入下面的界面。
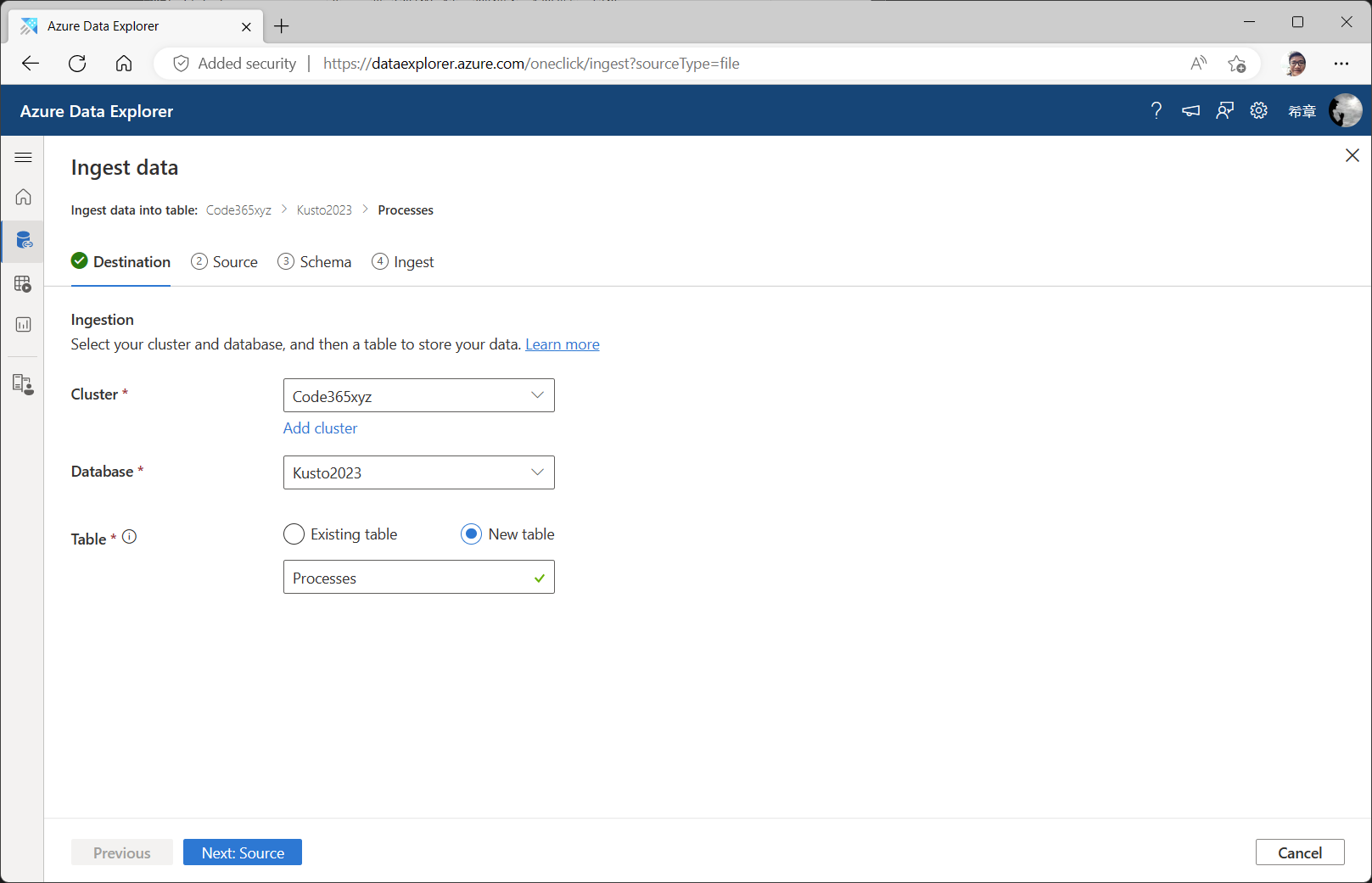
设置好Cluster,Database,并选择 New Table选项,输入新的表的名称后点击 ”Next: Source“ 按钮来选择上传的文件。
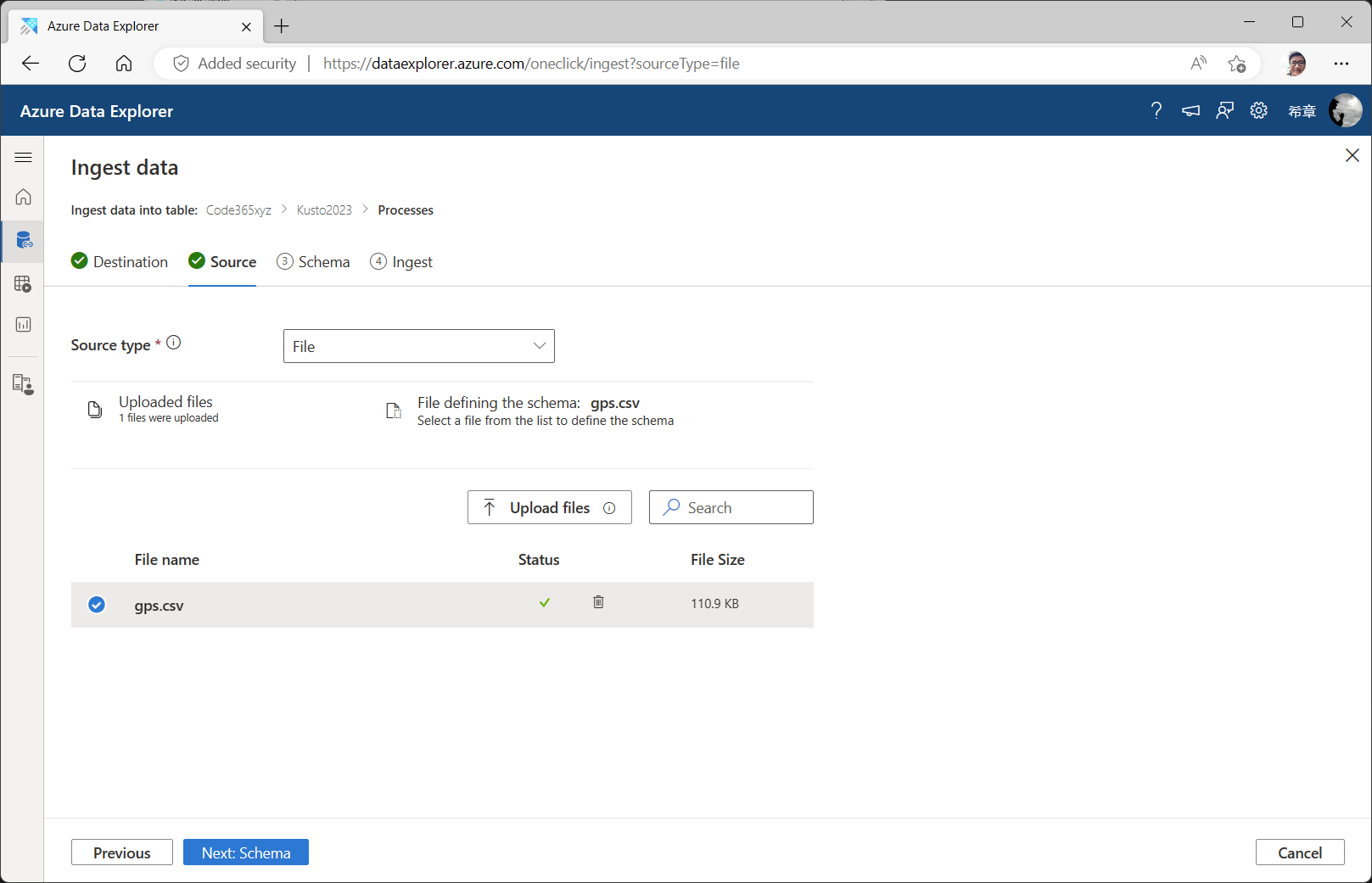
将文件拖放到这个界面,也可以点击 ”Upload files“按钮来选择文件,这里可以选择最多1000个文件。如果一切准备就绪,则点击 ”Next:Scheme“按钮进入下一步。
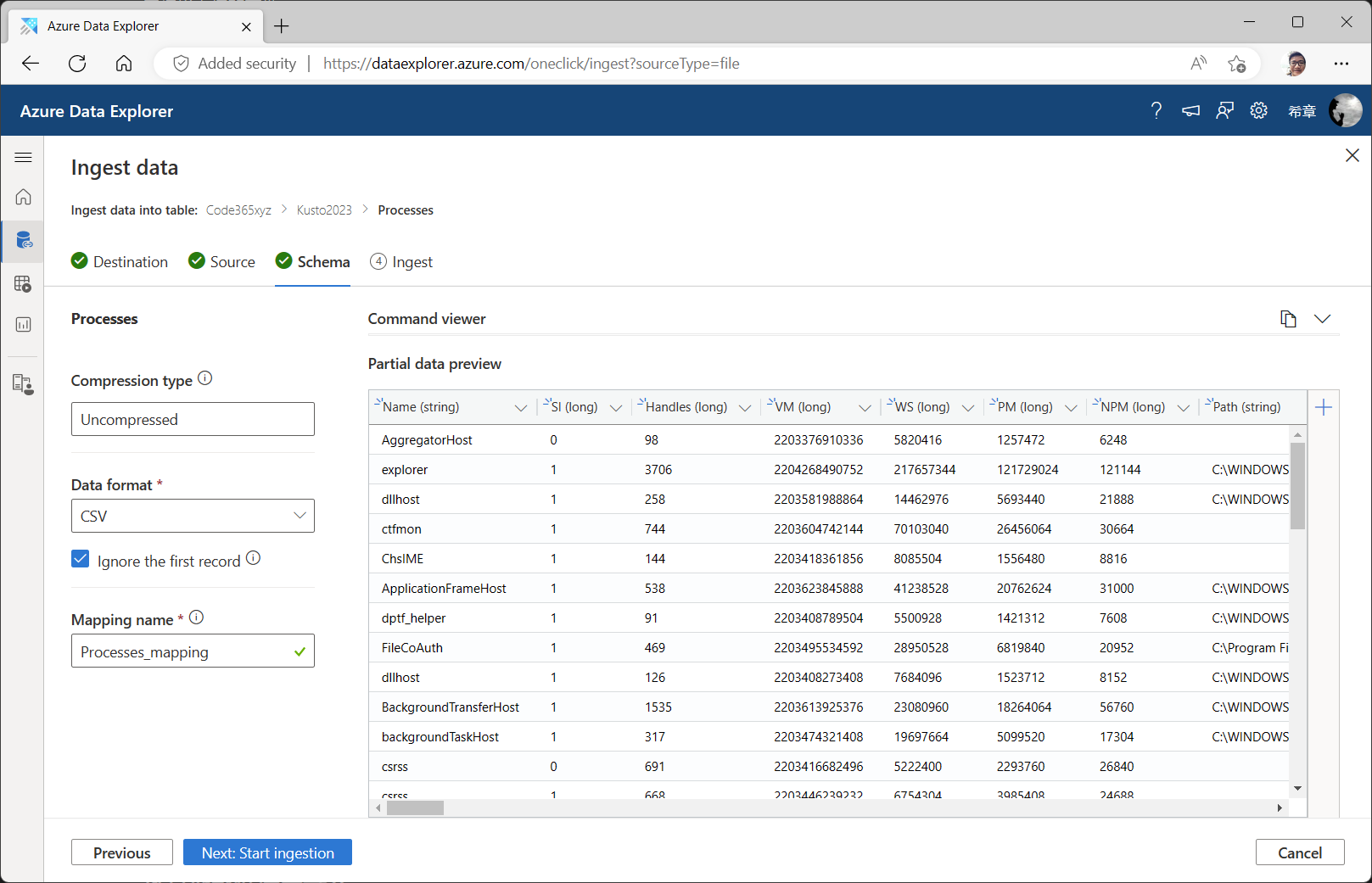
对于一些不甚复杂的文件,这个向导足够聪明,它会自动识别出来文件的格式、是否压缩、以及每个列的数据类型等。当然如果你不满意,也可以修改某些列的类型(但要注意,不恰当的数据类型修改,可能会导致数据丢失)。
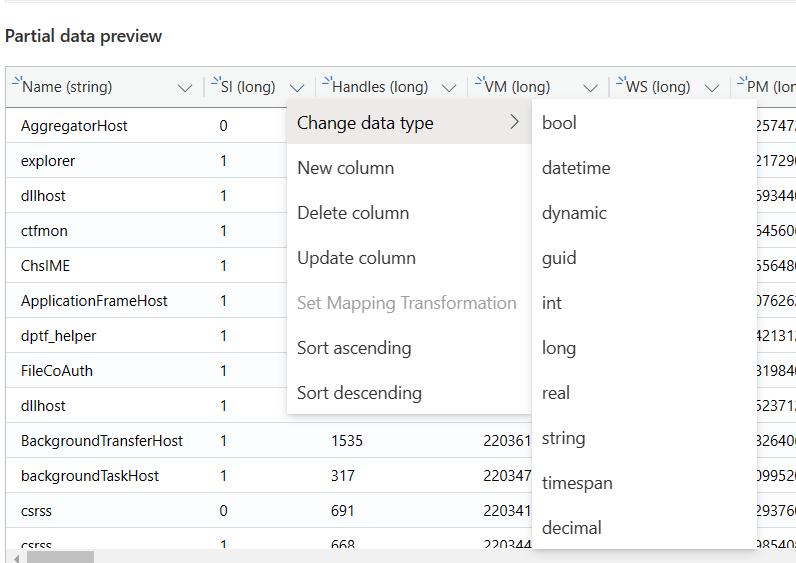
这个例子演示了如何将 Handles 这个字段的类型从 long 改为 int (点击字段右侧的下拉箭头,选择 Change data type , 然后选择 int ), 这样理论上占用的存储空间会小一些。
请留意界面的右侧位置有一个复制按钮,请先点击一下,并且将复制得到的内容放在合适位置,后续的练习会用到。

一切准备就绪了,请点击界面上的 ”Next:Start Ingestion“ 按钮开始导入。
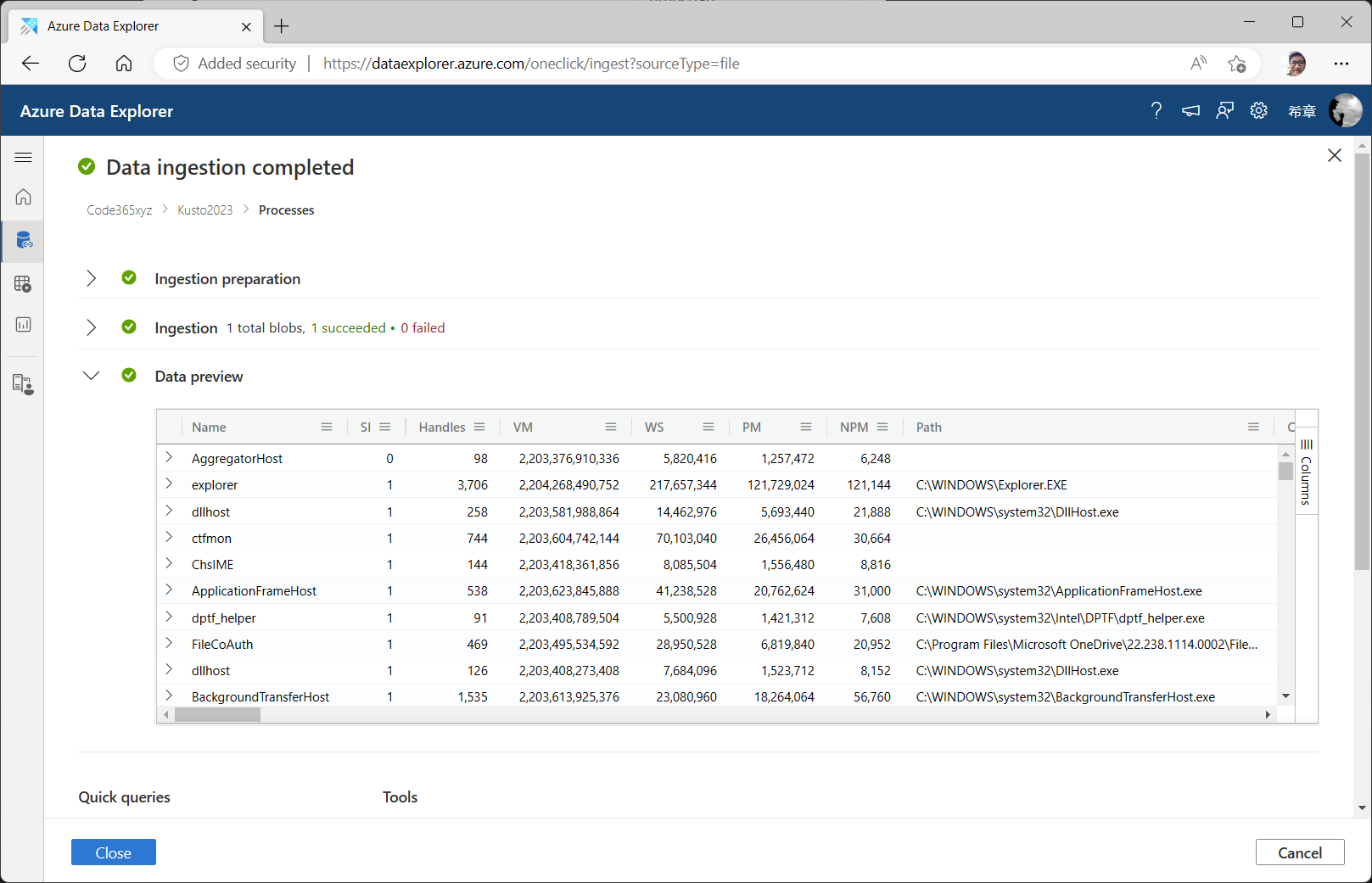
请等待导入完成后,点击 ”Close“ 按钮关闭当前窗口,进入查询窗口,我们通过如下的查询来验证一下数据。
Processes
| summarize sum(VM) by Company
| render piechart
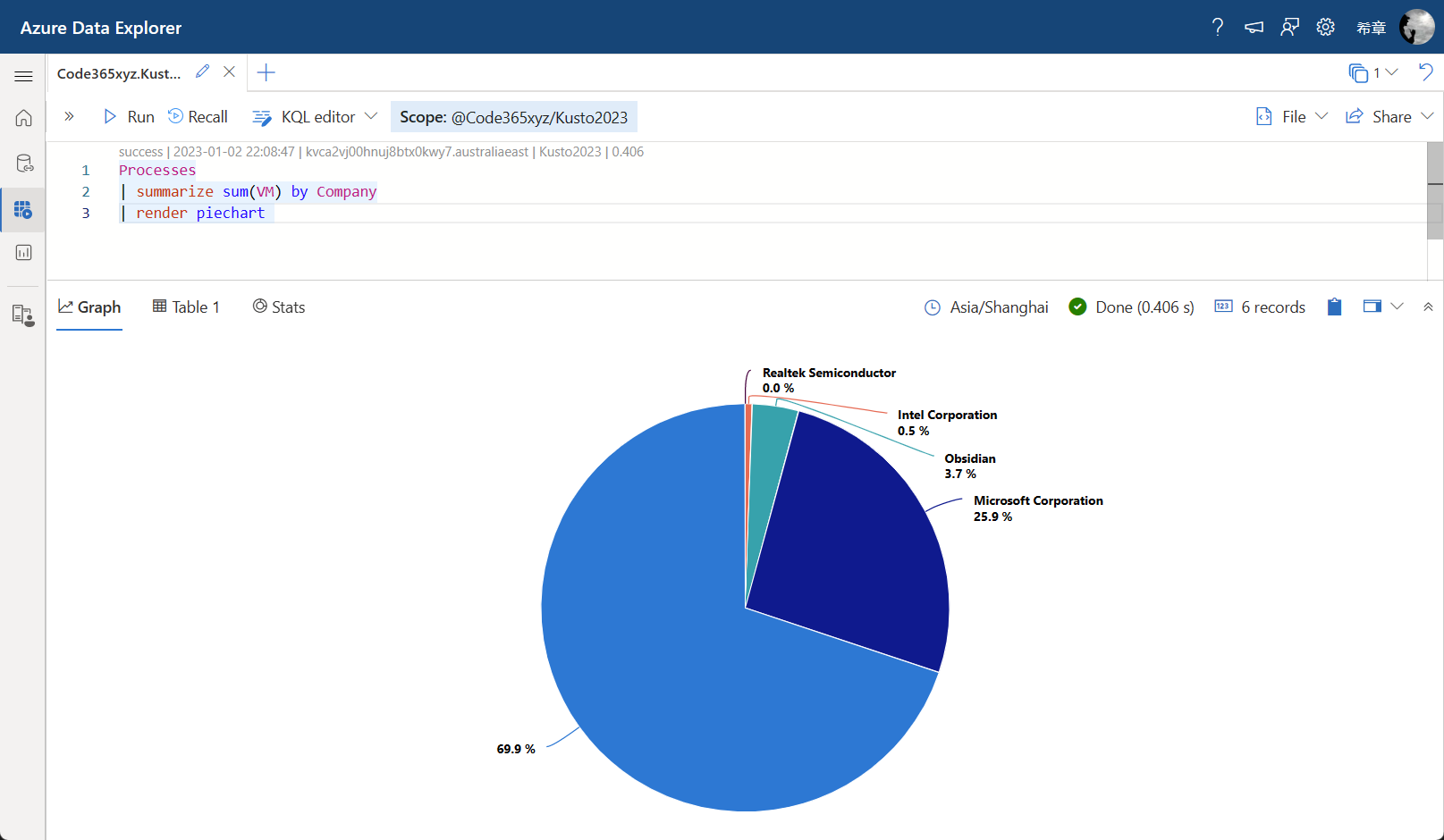
这个查询按照应用软件的厂商统计他们占用的内存数和比例。请注意,你那边的数据可能跟我不同,看到的结果也可能不一样。
请注意,你选择的文件其实是要先上传到一个临时的Azure Storage中去,使用完后会自动删除。所以如果你的文件较多,而且体积也不小,建议先做压缩。请注意,这里的压缩不是指你把多个文件直接打包为一个zip文件,这种情况下是无法识别的,你需要直接对单个文件进行压缩,而且需要用 gzip 进行压缩。
gzip 不是一个Windows自带的工具,你可以通过https://gnuwin32.sourceforge.net/packages/gzip.htm 下载得到它。如果你的电脑上安装了 git bash 这个工具,也可以很容易调用它。请参考下面的操作。
gzip gps.csv
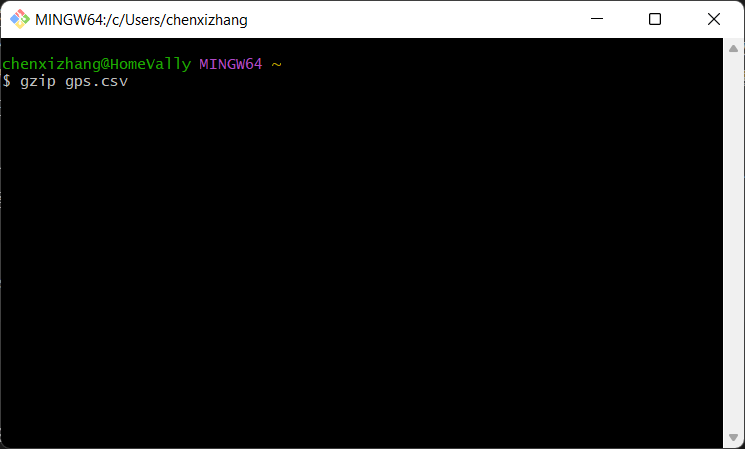
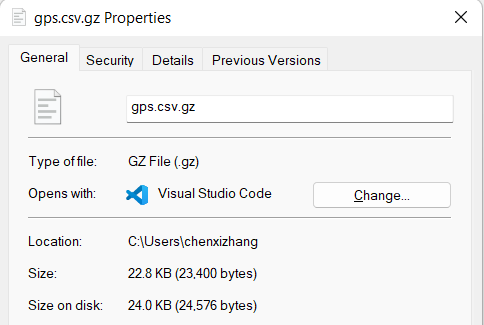
这个命令会生成一个 gps.csv.gz 的文件,原始文件就没有了(也就是说它是就地压缩),而它的体积大致为原文件的 1/6 ,如果你的网络带宽有限,且又需要上传大量的文件,这可能会带来很大的效率提升。
还有一个技巧,是可以将这个 gzip 的工具在你常用的PowerShell中定义一个快捷指令,如下所示
'New-Alias gz "C:\Program Files\Git\usr\bin\gzip.exe"' | Out-File -Append $profile
. $profile
以后就可以很方便地直接运行 gz 命令了。
从Azure Blob中导入
从本地文件上传虽然是过瘾的,但大部分时候,你的文件通常不在本地,这些文件可能来自于生产环境的日志,如果要实现从云端导入,目前来说,你需要将他们上传到一个公网可以访问到的地址,最好是Azure Blob Storage 中。
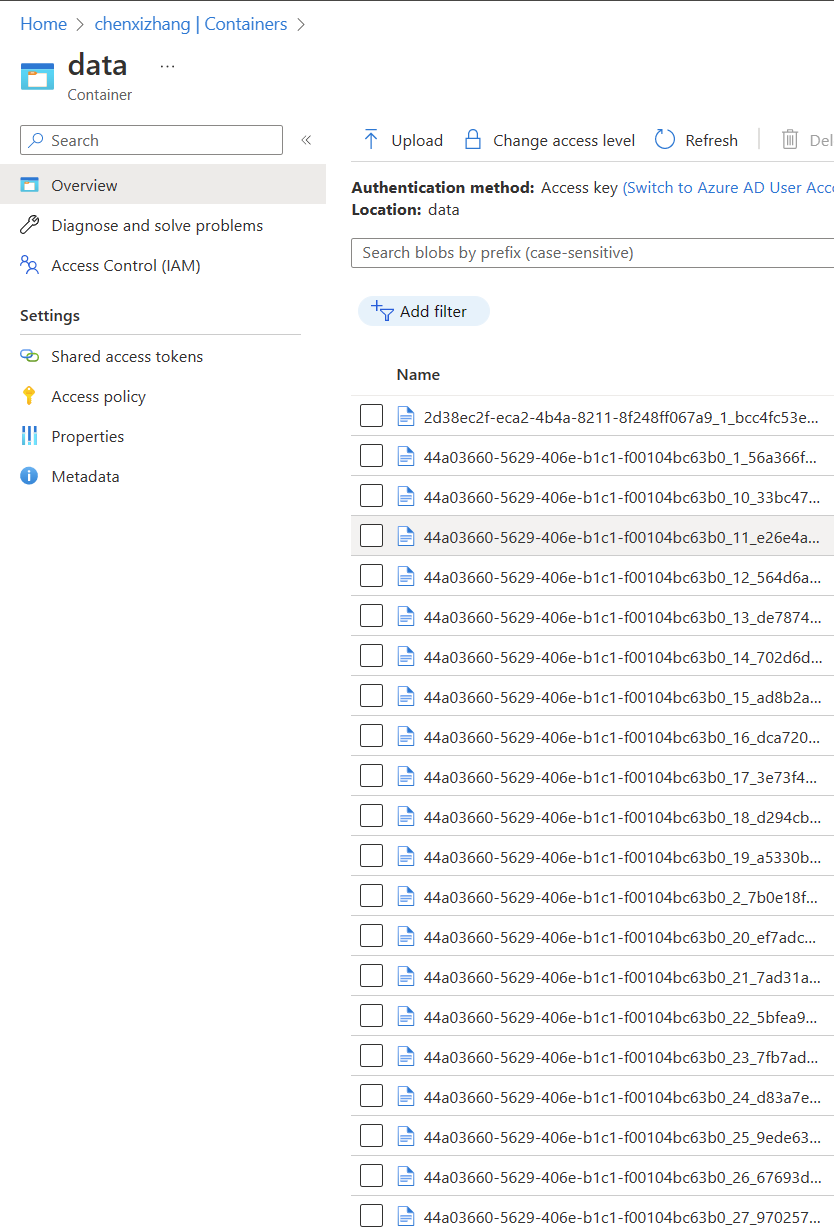
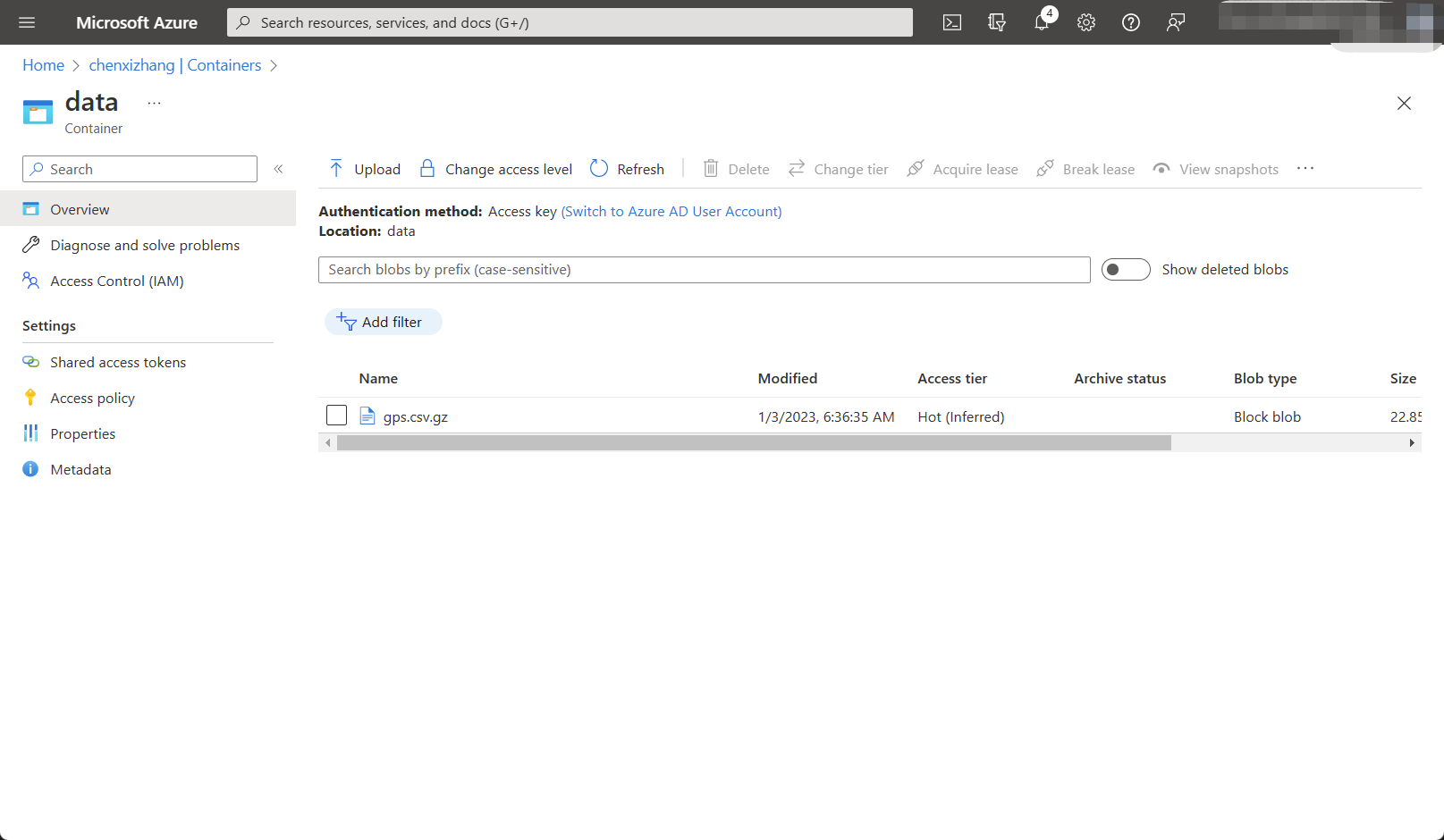
下图是一个例子,我有一个名称叫 chenxizhang 的存储账号(Storage account),然后在里面创建了一个叫 data 的容器(Container),然后我把刚才用到的 gps.csv.gz 这个文件上传到了这个容器。
为了能从这个文件进行导入,你需要得到一个可以直接访问它的地址,通常我们的 Container 对外都是无法直接访问的,但你可以为单独的文件生成一个SAS (shared access signature) 地址。
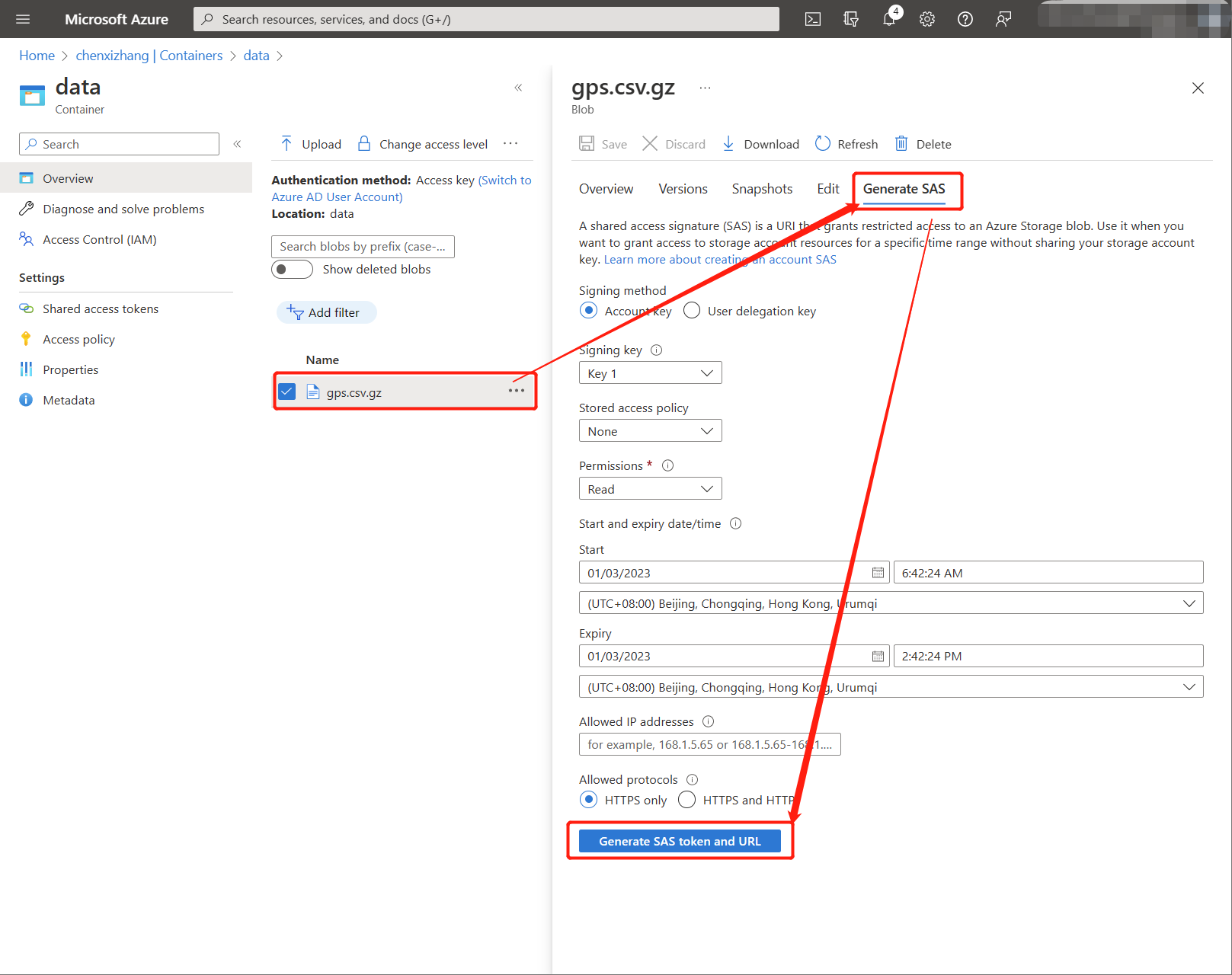
点击 ”Generate SAS token and URL“ 按钮后,复制最底部的地址。
那么接下来如何从这个文件导入数据呢?我们还是回到 Azure Data Explorer的 Ingest data 页面。因为此前我们从本地导入过一次,目标表已经创建出来了,所以这一次我们可以选择 ”Existing table“ 这个选项。
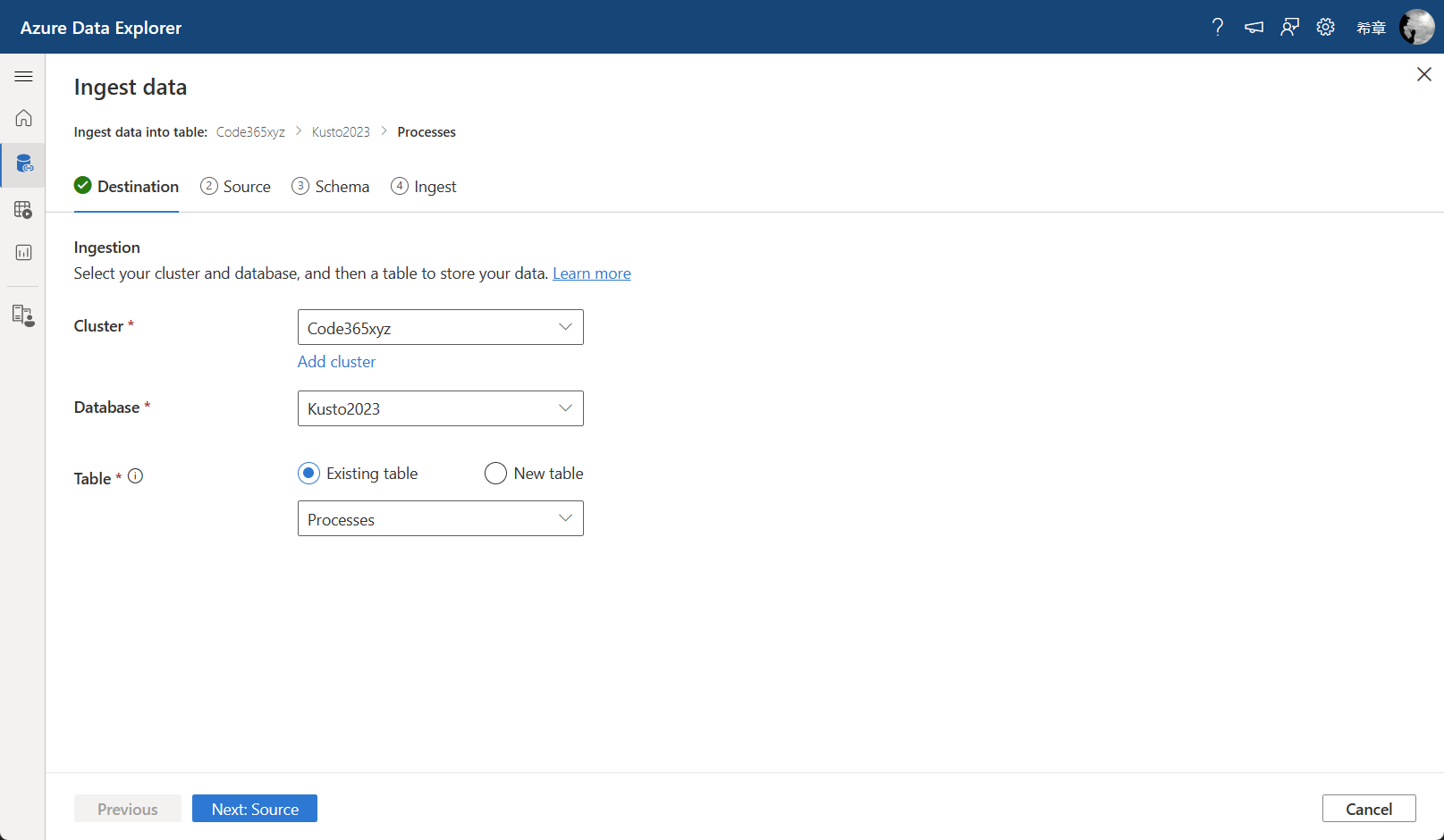
点击 ”Next:Source“ 按钮, 和之前不同的是,这里选择的 Source type 是 Blob,然后将你刚才复制的SAS 地址粘贴到 Link to source 这个框里面。
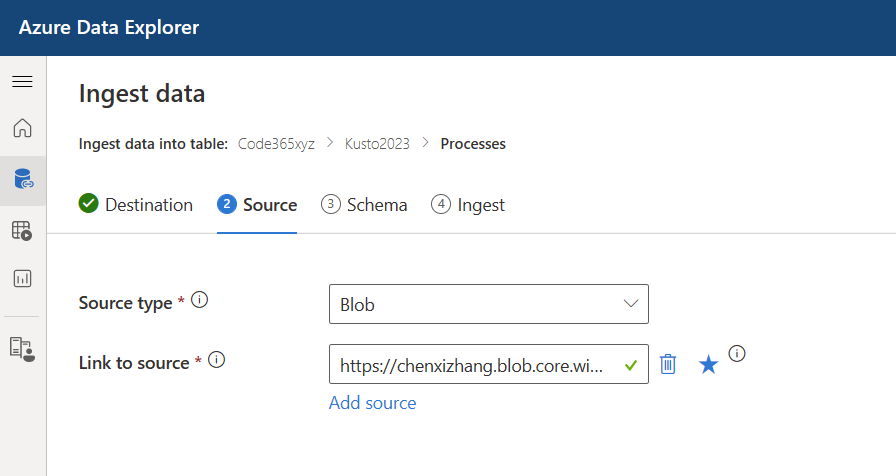
同样的,这个向导也能自动识别出来文件的格式,是否压缩,然后我们选择 ”Use existing mapping" 这个选项。

如果你的Blob文件本身是可以匿名访问的,则不需要生成SAS 地址。例如范例数据库中的StormEvents这个表,其实它就有一个匿名访问的地址(https://kustosamples.blob.core.windows.net/samplefiles/StormEvents.csv),你可以试一下。
一次性导入多个Blob文件
刚才我们导入了一个Blob文件,下面看看如何能实现一次性导入多个Blob文件。其实很简单,你只需要把所有的同类文件都放在一个Container下面即可。
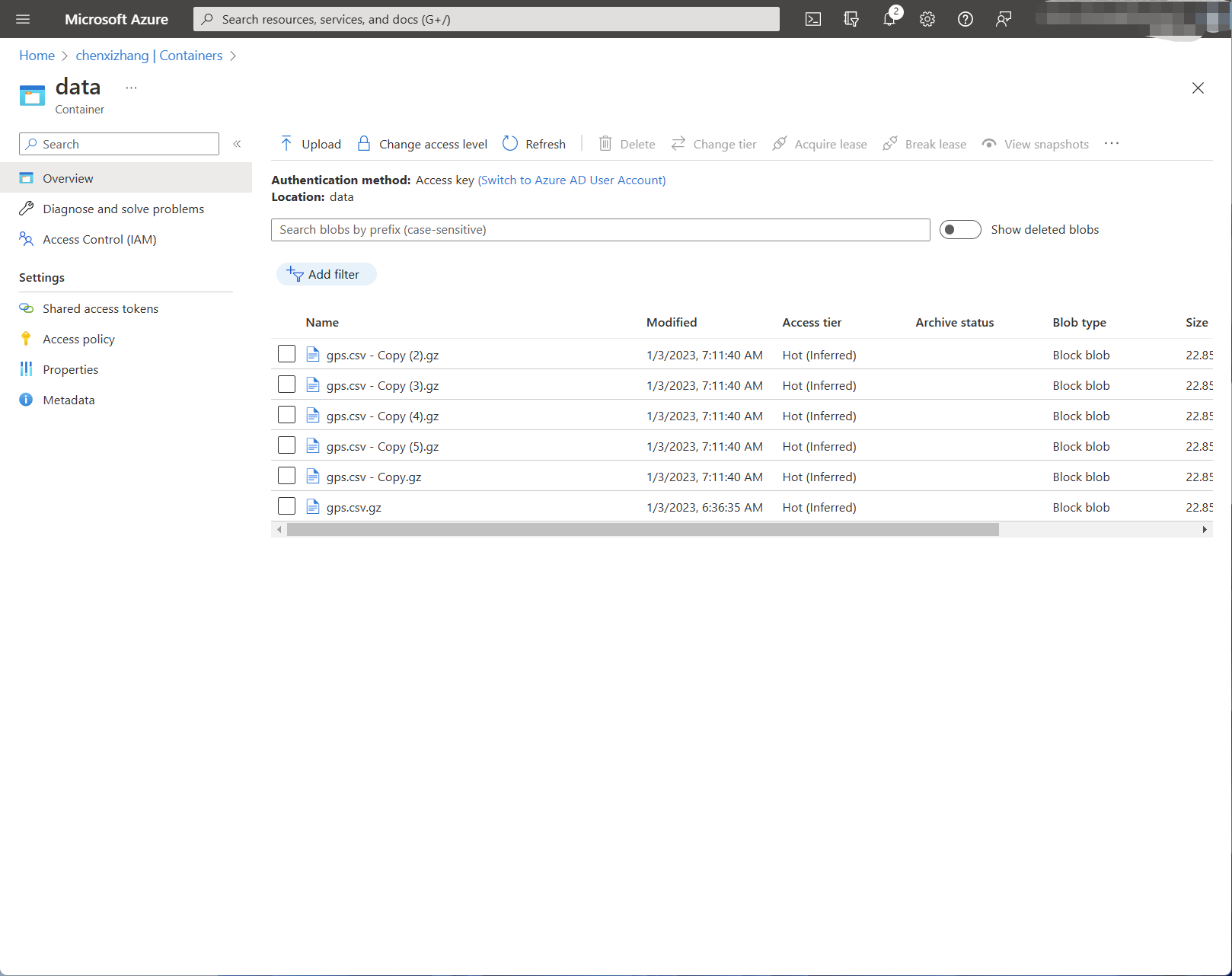
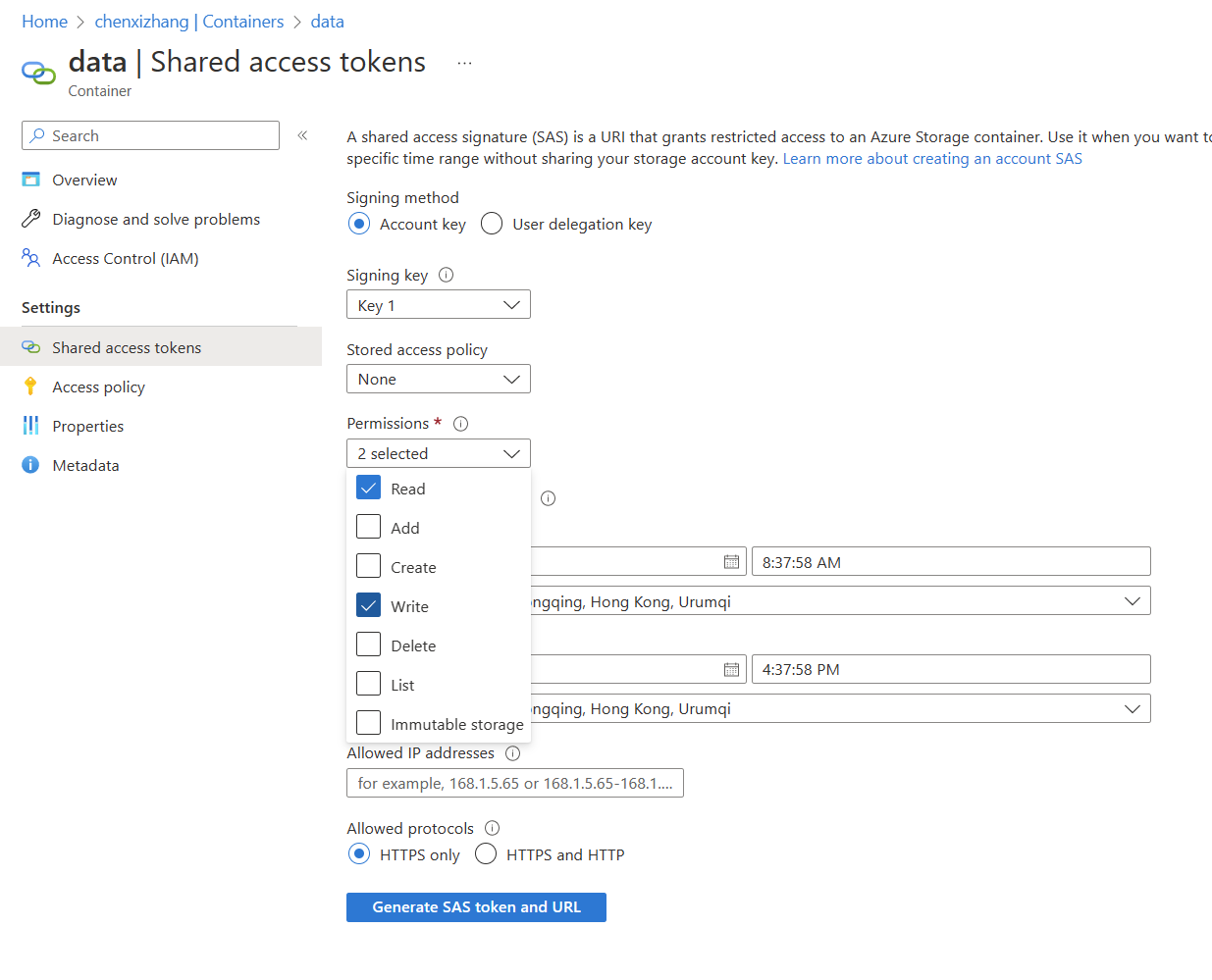
同样,为了访问这个Container,我们需要为它生成SAS URL。请注意,因为要列出所有的文件,所以在权限这里需要申请 List 的权限。
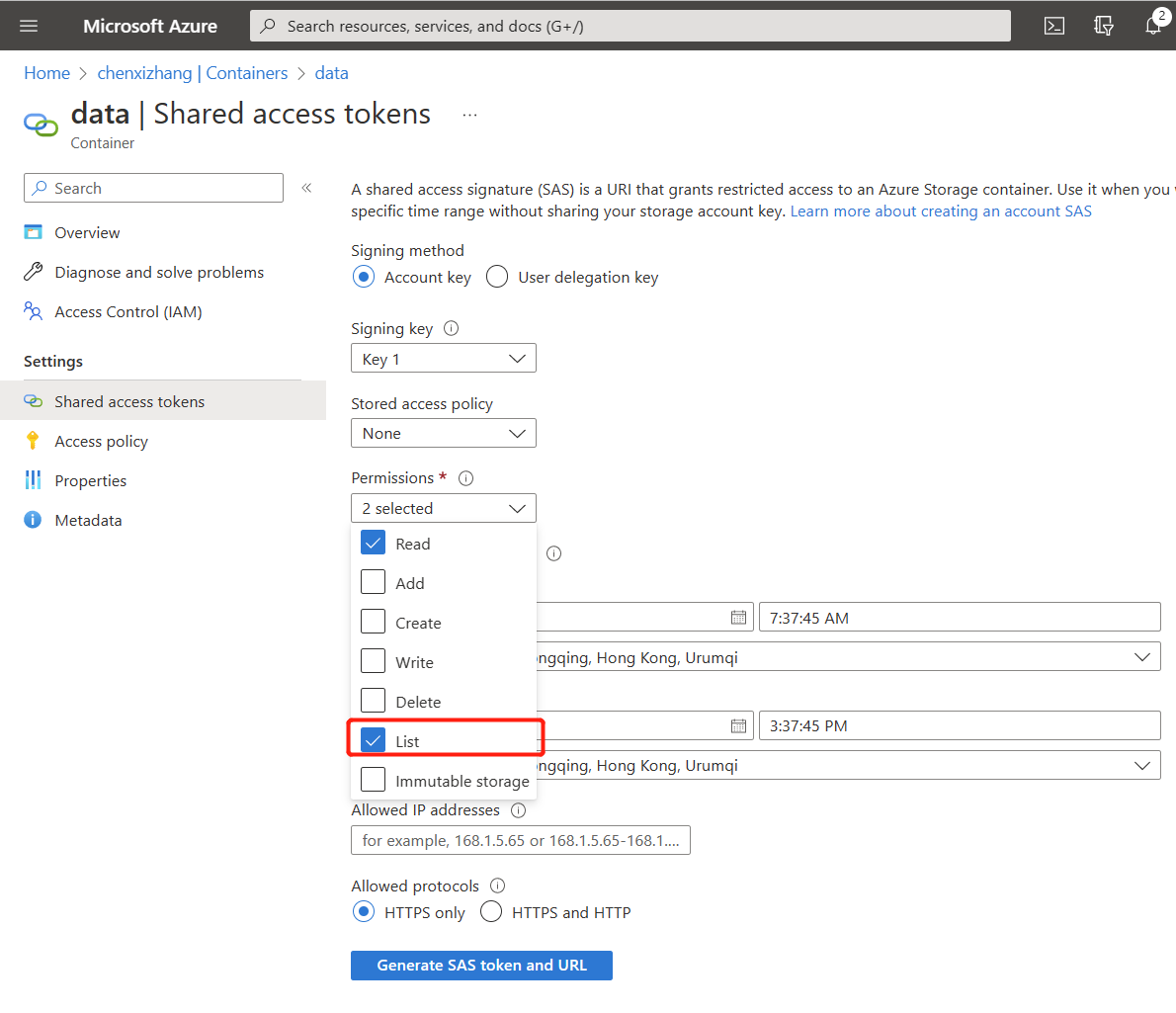
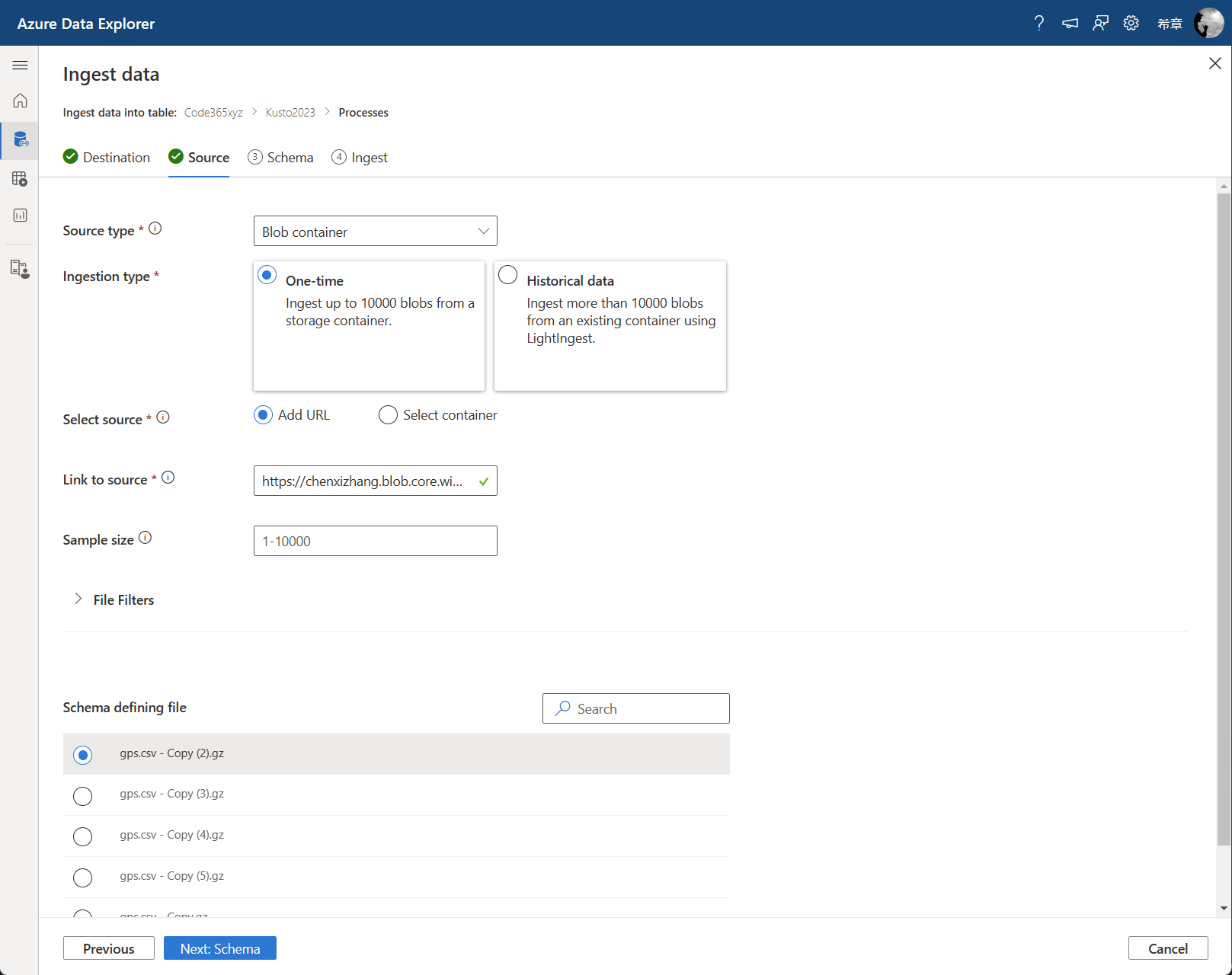
生成这个SAS地址后,你就可以在导入向导页面中,选择Source type 为 Blob container,然后将复制得到的SAS 地址,填入到 Link to source 这个框里面。
如果你细心的话, 在 Source type 的下拉列表中,还有一个 ADLS Gen2 Container, 它跟这里介绍的Blob Container没有本质上的不同,只是它是一种更加先进的存储账号类型, ADLS 的意思是 Azure data lake storage, Gen2是指第二代的意思。关于它的介绍,如果你有兴趣,可以参考 https://learn.microsoft.com/en-us/azure/storage/blobs/data-lake-storage-introduction 。
用控制命令导入数据
上面我们都是用图形化界面来实现导入,这本身很好,也不丢人。但如果你需要导入大量的文件,或者需要自动化导入的过程,或你就是一个纯粹地喜欢自己写代码的极客,你可能会想了解所谓的控制命令导入数据的方式。
还记得我之前提醒大家在导入的界面上复制操作命令吗? 如果你没有忘记保存起来,那么它看起来是像下面这样的。
// 创建表
////////////////////////////////////////////////////////////
.create table ['Processes'] (['Name']:string, ['SI']:long, ['Handles']:long, ['VM']:long, ['WS']:long, ['PM']:long, ['NPM']:long, ['Path']:string, ['CommandLine']:string, ['Parent']:string, ['Company']:string, ['CPU']:real, ['FileVersion']:string, ['ProductVersion']:string, ['Description']:string, ['Product']:string, ['__NounName']:string, ['SafeHandle']:string, ['Handle']:long, ['BasePriority']:long, ['ExitCode']:string, ['HasExited']:bool, ['StartTime']:datetime, ['ExitTime']:string, ['Id']:long, ['MachineName']:string, ['MaxWorkingSet']:long, ['MinWorkingSet']:long, ['Modules']:string, ['NonpagedSystemMemorySize64']:long, ['NonpagedSystemMemorySize']:long, ['PagedMemorySize64']:long, ['PagedMemorySize']:long, ['PagedSystemMemorySize64']:long, ['PagedSystemMemorySize']:long, ['PeakPagedMemorySize64']:long, ['PeakPagedMemorySize']:long, ['PeakWorkingSet64']:long, ['PeakWorkingSet']:long, ['PeakVirtualMemorySize64']:long, ['PeakVirtualMemorySize']:long, ['PriorityBoostEnabled']:bool, ['PriorityClass']:string, ['PrivateMemorySize64']:long, ['PrivateMemorySize']:long, ['ProcessorAffinity']:long, ['SessionId']:long, ['StartInfo']:string, ['Threads']:string, ['HandleCount']:long, ['VirtualMemorySize64']:long, ['VirtualMemorySize']:long, ['EnableRaisingEvents']:bool, ['StandardInput']:string, ['StandardOutput']:string, ['StandardError']:string, ['WorkingSet64']:long, ['WorkingSet']:long, ['SynchronizingObject']:string, ['MainModule']:string, ['PrivilegedProcessorTime']:timespan, ['TotalProcessorTime']:timespan, ['UserProcessorTime']:timespan, ['ProcessName']:string, ['MainWindowHandle']:long, ['MainWindowTitle']:string, ['Responding']:bool, ['Site']:string, ['Container']:string)
// 创建字段映射
////////////////////////////////////////////////////////////
.create table ['Processes'] ingestion csv mapping 'Processes_mapping' '[{"column":"Name", "Properties":{"Ordinal":"0"}},{"column":"SI", "Properties":{"Ordinal":"1"}},{"column":"Handles", "Properties":{"Ordinal":"2"}},{"column":"VM", "Properties":{"Ordinal":"3"}},{"column":"WS", "Properties":{"Ordinal":"4"}},{"column":"PM", "Properties":{"Ordinal":"5"}},{"column":"NPM", "Properties":{"Ordinal":"6"}},{"column":"Path", "Properties":{"Ordinal":"7"}},{"column":"CommandLine", "Properties":{"Ordinal":"8"}},{"column":"Parent", "Properties":{"Ordinal":"9"}},{"column":"Company", "Properties":{"Ordinal":"10"}},{"column":"CPU", "Properties":{"Ordinal":"11"}},{"column":"FileVersion", "Properties":{"Ordinal":"12"}},{"column":"ProductVersion", "Properties":{"Ordinal":"13"}},{"column":"Description", "Properties":{"Ordinal":"14"}},{"column":"Product", "Properties":{"Ordinal":"15"}},{"column":"__NounName", "Properties":{"Ordinal":"16"}},{"column":"SafeHandle", "Properties":{"Ordinal":"17"}},{"column":"Handle", "Properties":{"Ordinal":"18"}},{"column":"BasePriority", "Properties":{"Ordinal":"19"}},{"column":"ExitCode", "Properties":{"Ordinal":"20"}},{"column":"HasExited", "Properties":{"Ordinal":"21"}},{"column":"StartTime", "Properties":{"Ordinal":"22"}},{"column":"ExitTime", "Properties":{"Ordinal":"23"}},{"column":"Id", "Properties":{"Ordinal":"24"}},{"column":"MachineName", "Properties":{"Ordinal":"25"}},{"column":"MaxWorkingSet", "Properties":{"Ordinal":"26"}},{"column":"MinWorkingSet", "Properties":{"Ordinal":"27"}},{"column":"Modules", "Properties":{"Ordinal":"28"}},{"column":"NonpagedSystemMemorySize64", "Properties":{"Ordinal":"29"}},{"column":"NonpagedSystemMemorySize", "Properties":{"Ordinal":"30"}},{"column":"PagedMemorySize64", "Properties":{"Ordinal":"31"}},{"column":"PagedMemorySize", "Properties":{"Ordinal":"32"}},{"column":"PagedSystemMemorySize64", "Properties":{"Ordinal":"33"}},{"column":"PagedSystemMemorySize", "Properties":{"Ordinal":"34"}},{"column":"PeakPagedMemorySize64", "Properties":{"Ordinal":"35"}},{"column":"PeakPagedMemorySize", "Properties":{"Ordinal":"36"}},{"column":"PeakWorkingSet64", "Properties":{"Ordinal":"37"}},{"column":"PeakWorkingSet", "Properties":{"Ordinal":"38"}},{"column":"PeakVirtualMemorySize64", "Properties":{"Ordinal":"39"}},{"column":"PeakVirtualMemorySize", "Properties":{"Ordinal":"40"}},{"column":"PriorityBoostEnabled", "Properties":{"Ordinal":"41"}},{"column":"PriorityClass", "Properties":{"Ordinal":"42"}},{"column":"PrivateMemorySize64", "Properties":{"Ordinal":"43"}},{"column":"PrivateMemorySize", "Properties":{"Ordinal":"44"}},{"column":"ProcessorAffinity", "Properties":{"Ordinal":"45"}},{"column":"SessionId", "Properties":{"Ordinal":"46"}},{"column":"StartInfo", "Properties":{"Ordinal":"47"}},{"column":"Threads", "Properties":{"Ordinal":"48"}},{"column":"HandleCount", "Properties":{"Ordinal":"49"}},{"column":"VirtualMemorySize64", "Properties":{"Ordinal":"50"}},{"column":"VirtualMemorySize", "Properties":{"Ordinal":"51"}},{"column":"EnableRaisingEvents", "Properties":{"Ordinal":"52"}},{"column":"StandardInput", "Properties":{"Ordinal":"53"}},{"column":"StandardOutput", "Properties":{"Ordinal":"54"}},{"column":"StandardError", "Properties":{"Ordinal":"55"}},{"column":"WorkingSet64", "Properties":{"Ordinal":"56"}},{"column":"WorkingSet", "Properties":{"Ordinal":"57"}},{"column":"SynchronizingObject", "Properties":{"Ordinal":"58"}},{"column":"MainModule", "Properties":{"Ordinal":"59"}},{"column":"PrivilegedProcessorTime", "Properties":{"Ordinal":"60"}},{"column":"TotalProcessorTime", "Properties":{"Ordinal":"61"}},{"column":"UserProcessorTime", "Properties":{"Ordinal":"62"}},{"column":"ProcessName", "Properties":{"Ordinal":"63"}},{"column":"MainWindowHandle", "Properties":{"Ordinal":"64"}},{"column":"MainWindowTitle", "Properties":{"Ordinal":"65"}},{"column":"Responding", "Properties":{"Ordinal":"66"}},{"column":"Site", "Properties":{"Ordinal":"67"}},{"column":"Container", "Properties":{"Ordinal":"68"}}]'
// 导入数据
///////////////////////////////////////////////////////////
.ingest async into table ['Processes'] (h'<blob path to upload>') with (format='csv',ingestionMappingReference='Processes_mapping',ingestionMappingType='csv',tags="['fa331bbd-c940-4630-8c2e-d5b20ec304dc']",ignoreFirstRecord=true)
第一步(创建表)和第二步(创建映射)并不是每次都需要执行,而第三步(导入数据),其实你要替换的就是 <blob path to upload> 这里的信息就可以了。
当然,要用这个脚本来执行,你的文件必须已经放到了云端,并且生成了SAS 地址。
这里其实还有一个小技巧。大家有没有发现,上面这一大堆代码中,其实占据主要部分的是创建表结构和映射,当表的字段不是很多时,这并不难,但如果字段超过十个,你就会觉得手工写那些字段名和他们的数据类型,会很吃力。那么有没有一种办法从一个外部文件自动得到表结构,并且用于来创建表呢?
下面我们看看如何根据一个容器,自动生成表结构,并且用几行简单的命令来实现导入吧。
let options = dynamic({
'StorageContainers': [
h@'https://chenxizhang.blob.core.windows.net/data?sp=rl&st=2023-01-02T23:37:45Z&se=2023-01-03T07:37:45Z&spr=https&sv=2021-06-08&sr=c&sig=439I73xNeFPsAtrXKFVJlLC3cnFGqoZeCrkRi6eFy6w%3D'
],
'FileExtension': '.csv.gz',
'DataFormat': 'csv'
});
evaluate infer_storage_schema(options)
这个查询使用了一个插件(infer_storage_schema),它返回的结果只有一个字段,它包含所有字段的定义,并且用一个字符串表示,你可以用它来快速创建你的表了。

从其他数据库中导入
除了从文件中导入数据,另外一种经常用的方式是从别的数据库中复制数据,这个数据可以是原始数据,也可以是聚合过之后的计算结果。
假设我们现在想把范例数据库中的 StormEvents 表完整地复制到自己的数据库,你可以尝试下面的查询。
.set-or-append StormEvents <|
cluster('help').database('Samples').StormEvents
.set-or-append 是一个控制命令,我们不在这一季中过多地展开,只是在用到时就用一下。这个命令的意思是创建新表或者向现有表追加数据。这个命令的好处是连创建表的语法都不需要了。
<| 这个指令是指把后面查询的结果,输出到前面的目标表。目标表可以是同一个数据库,也可以是其他数据库,甚至其他群集。
下面再来看一个更加复杂一点的,把计算结果追加到目标表中。
.set-or-append StateSummarization <|
cluster('help').database('Samples').StormEvents
| summarize
count = count(),
crops = sum(DamageCrops),
property= sum(DamageProperty)
by
State,
bin(StartTime, 1d)
其实认真说起来,除了行数多一点之外,这个查询也没有什么复杂的。
导出数据
本章的最后我们研究一下如何在需要时将查询的数据导出,包括导出到本地csv文件,以及导出到云端的Blob文件。
导出本地csv文件
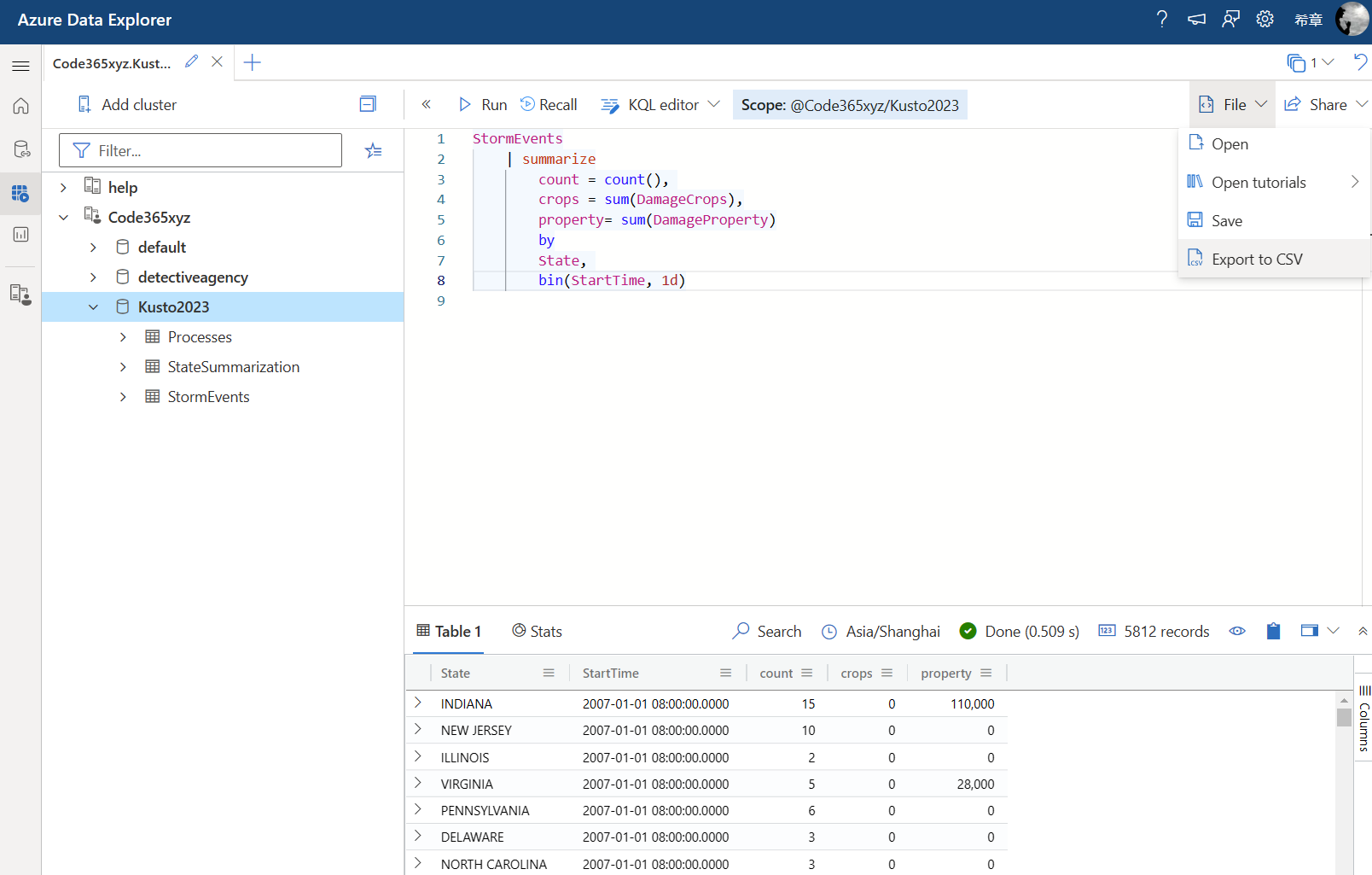
要导出你的数据,你只需要编写好查询,然后确定得到了你想要的数据,最后在工具栏中点击 “File”下拉菜单中的 “Export to CSV” 即可。
📣要执行这个操作,还有一个快捷方式,就是先按下 F1 键,呼唤出命令窗口,然后输入 export,回车即可。
如果你使用本地的 Kusto.explorer 这个工具,则导出的选项会多一点,但说实话,导出csv 是最常见的了。
导出到Blob文件
那么,如果我想把查询结果导出到云端呢?首先你需要准备一个容器(Container),并且生成一个包含了 Write 权限的SAS URL。
.export async compressed to csv
(h'https://chenxizhang.blob.core.windows.net/data?sp=rw&st=2023-01-02T23:37:45Z&se=2023-01-03T07:37:45Z&spr=https&sv=2021-06-08&sr=c&sig=pxWNDEcr2tMzkXOp8iY%2F0RuZ8mLOsLUmJbyJq5kpn6A%3D')
with (includeHeaders='all') <|
StormEvents
| summarize
count = count(),
crops = sum(DamageCrops),
property= sum(DamageProperty)
by
State,
bin(StartTime, 1d)
执行这个命令会在目标的容器中生成一个随机的文件(以.csv.gz 为扩展名),你甚至还可以为一个查询生成多个文件(即按一定的大小自动拆分文件),只要设置 sizeLimit 的选项值就可以了(以字节为单位)。
.export async compressed to csv
(h'https://chenxizhang.blob.core.windows.net/data?sp=rw&st=2023-01-02T23:37:45Z&se=2023-01-03T07:37:45Z&spr=https&sv=2021-06-08&sr=c&sig=pxWNDEcr2tMzkXOp8iY%2F0RuZ8mLOsLUmJbyJq5kpn6A%3D')
with (
includeHeaders='all',
sizeLimit =100000
) <|
StormEvents
| summarize
count = count(),
crops = sum(DamageCrops),
property= sum(DamageProperty)
by
State,
bin(StartTime, 1d)
文件名并不重要,因为如果你以后导入时,其实也不需要知道具体的文件名,只要通过容器导入即可。这真是太强大了。