第二章:KQL 核心
作者:陈希章,2023年1月 于上海 专栏:大数据分析新玩法之Kusto宝典 第一季:一元初始 反馈:ares@xizhang.com
这一章将重点展开 KQL 查询语言,也是这一季的核心内容,因为使用Kusto 最核心的任务就是查询数据。当然由于KQL 本身的内容非常多(函数和操作符有几百个那么多),限于篇幅,我们肯定没有办法面面俱到,同时考虑到这一季是入门的知识,所以会尽量包括最基本的部分,目标是希望读者能快速掌握 KQL 并且用到最常见的查询场景中去。
再论启发式和探索式
我不止一次提到 启发式 和 探索式 这两个词,这是 KQL 为我带来的最大惊喜。这两个术语的意思是指,不需要借助任何预先编写的文档,通过 KQL 本身就可以由浅至深地了解某个数据集,并且在了解过程中,不断地得到启发,而随着这种探索的推进,你最后对数据集能烂熟于心,有可能做出一些之前都预想不到的分析场景。这可能才是数据分析的未来,也是Kusto 区别于其他传统数据分析工具的根本。
既然要学习数据查询,当然离不开数据。在第一章其实已经提到了如何连接到范例数据库 (https://dataexplorer.azure.com/clusters/help/databases/Samples ,并且还蜻蜓点水一样地介绍了几个查询,其中已经提到一个表格 StormEvents , 包含了2007年美国境内发生过的所有暴风雨的数据。这一章我们也将重点使用这个表格来作为范例数据。为此,我们需要对它多一点了解。
了解元数据
我们就以这个表为例,来体验一下这种启发和探索的过程吧。如果你想快速了解Kusto数据库中的某个表的基本情况,你可以通过执行下面的控制命令。
.show table StormEvents
📣控制命令都是以 . 开头的,以便区别于KQL 查询。本书暂时不会对控制命令的细节进行展开,你只要在需要时跟着使用它们即可。
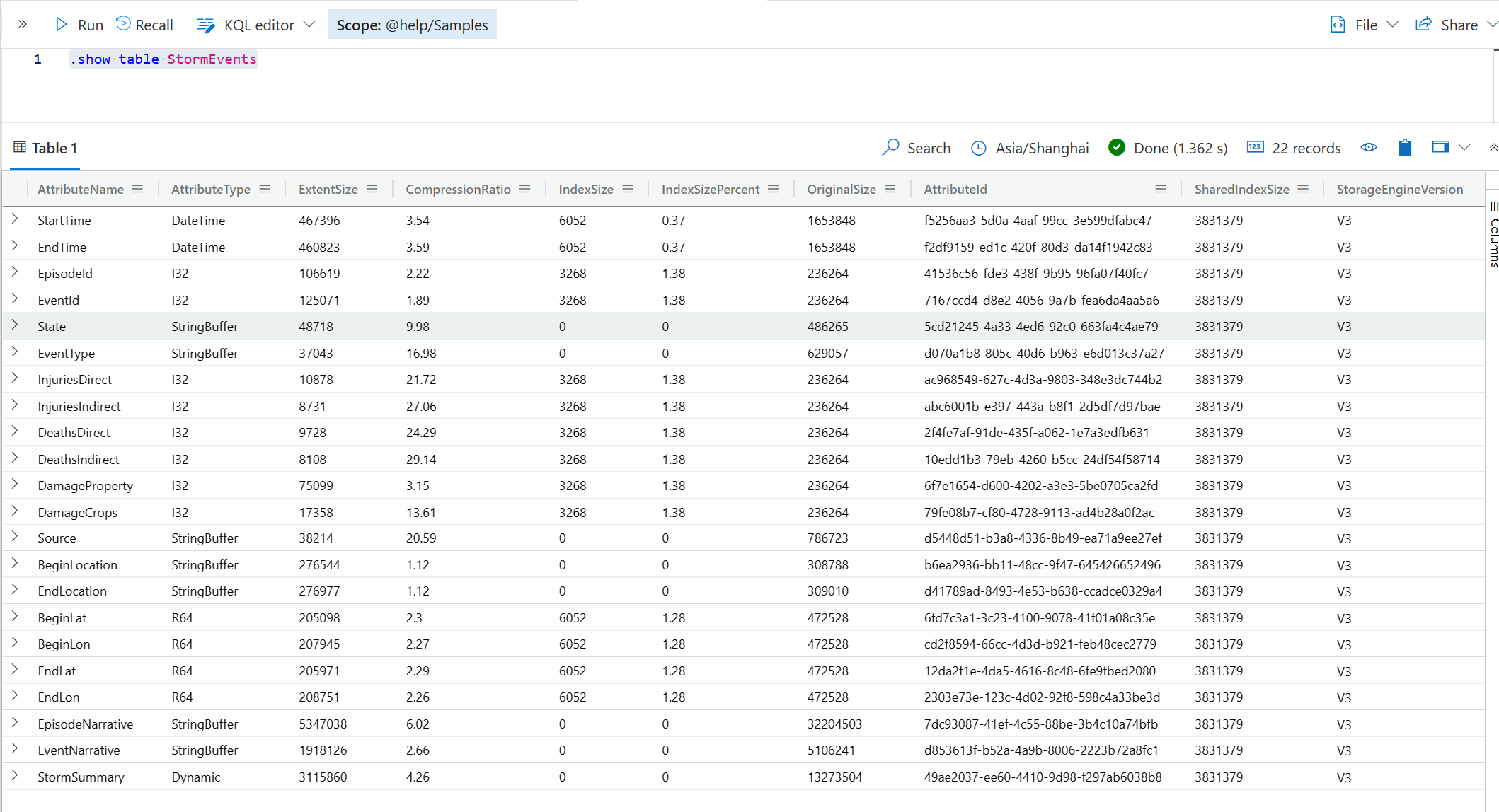
这里的 Attribute 其实指的就是字段 (Column),通过上表你可以看到所有的字段名称,数据类型,是否做了索引或压缩,所占的存储空间,甚至还能知道当前使用的引擎版本。
这一步的时候,我建议你花一点时间认真看一下字段名称,并且在你的脑海中尝试建立对他们的一个直观认识,并且开始想象他们会是什么样的数据,可以用来产生哪些分析的场景和效果。例如这个表中,它有下面的字段,我把我在第一眼看到时的联想也记录下来。
| 字段名 | 含义 | 联想 |
|---|---|---|
| StartTime | 开始时间 | 用时间段来分析是最常见的 |
| EndTime | 结束时间 | 结束时间如果减去开始时间的话,可以计算得到时长,而时长也是一个很好的信息 |
| BeginLat | 开始纬度 | 有经纬度信息的话,也许可以画在地图上 |
| BeginLon | 开始经度 | 同上 |
| EndLat | 结束纬度 | 同上 |
| EndLon | 结束经度 | 同上 |
| BeginLocation | 开始的地理位置(文本表示) | 这个可以用来做分类统计 |
| EndLocation | 结束的地理位置(文本表示) | 同上 |
| State | 所属的州 | 同上 |
| EventType | 事件类型 | 同上 |
| Source | 数据来源 | 同上 |
| InjuriesDirect | 直接受伤人数 | 这些是度量值,可以用来显示统计值,趋势等 |
| InjuriesIndirect | 间接受伤人数 | 同上 |
| DeathsDirect | 直接死亡人数 | 同上 |
| DeathsIndirect | 间接死亡人数 | 同上 |
| DamageProperty | 受灾财产损失 | 同上 |
| DamageCrops | 农作物损失 | 同上 |
| EpisodeId | 风暴的一个阶段编号 | 这个有意思,也许一个风暴,包括了几个阶段,例如台风形成,或者升级为强台风,最后退去等 |
| EventId | 事件的编号 | 一个阶段又包含了几个事件,例如某个台风在宁波登陆,然后在舟山登陆,这些具体登陆可能就是一个事件 |
| EpisodeNarrative | 阶段故事描述 | 这个一般用不到,除非是按关键字搜索用 |
| EventNarrative | 事件故事描述 | 同上 |
| StormSummary | 整个风暴的总结 | 同上 |
所以,其实你可以归类一下,这个表中有时间信息(多个时间可以组成一个时间轴,描述事件发生的轨迹等),地理信息(包括精准的经纬度,以及具体的州县),分类信息,以及损失数据(可以用来做聚合计算等)。
接下来,你可能会有兴趣了解一下,这些个字段到底包含了多少数据呢,分别在分布上有什么特征呢?你可以尝试一下 .show table StormEvents column statistics 这个命令。

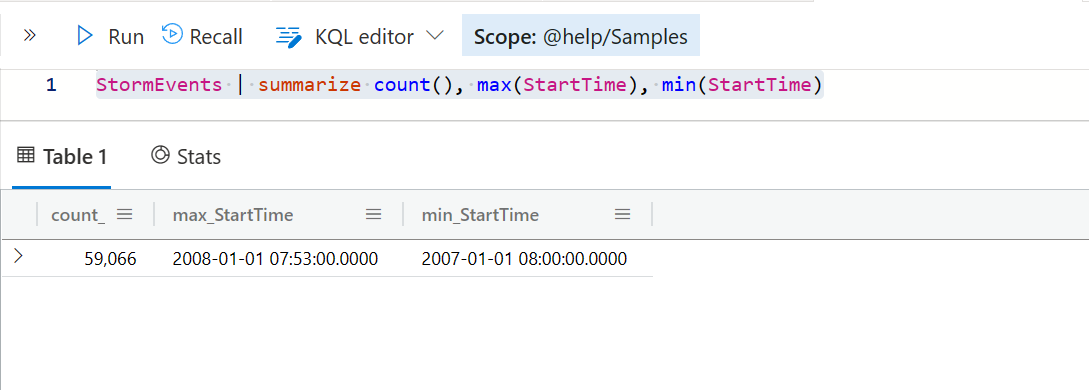
通过这个结果,我们可以了解,这个表的行数应该有 59066, 然后针对那些不是唯一值的字段(剔除了时间字段,地理字段等),你可以看到他们各自的基数(Cardinality),这个可以表示某个列唯一值的数量,例如 State 这个字段,其实它只有 67 个唯一的值。通过这个值的大小(或者他的范围),你可以大致知道哪些字段用来做分类汇总会更加合适。通常,这个值越小的话,查询和聚合计算的效率都会更高。
上表中还可以看出空值的行数,以及占总行数的比例。空值的单元格是无法避免的,但它会影响聚合计算,所以你需要额外小心空值比较多的字段。
咱们继续探索吧。通过 .show table StormEvents details , 你可以从另外一个侧面了解到这个表的一些信息,例如缓存的规则,数据存储的规则,合并策略等。

有点意思,如果你还不过瘾,其实还有更多可以探索的。
限于篇幅我们就不一一展开了,目前来说已经够用。接下来我就会对数据进行一些抽样,实际地考察一下,到底包含什么样的数据。
数据取样
取样的意思就是我随便看看,不要小看这种探索,你可以快速地浏览一下数据,甚至随机抽样,这样可以对数据有一个直观的认识,可以启发你构思后续的分析。
take, limit
这两个操作符(operator)其实是等价的,它们就是从目标数据集中抽取指定的行数返回。有意思的是,每次执行的结果可能是不一样的,除非你的结果集本身是排好序的,但这样做通常没有必要,我们反而是希望看到这种随机性。
如下例子,我在不同的浏览器窗口运行同一个命令,看到的结果是不一样的。
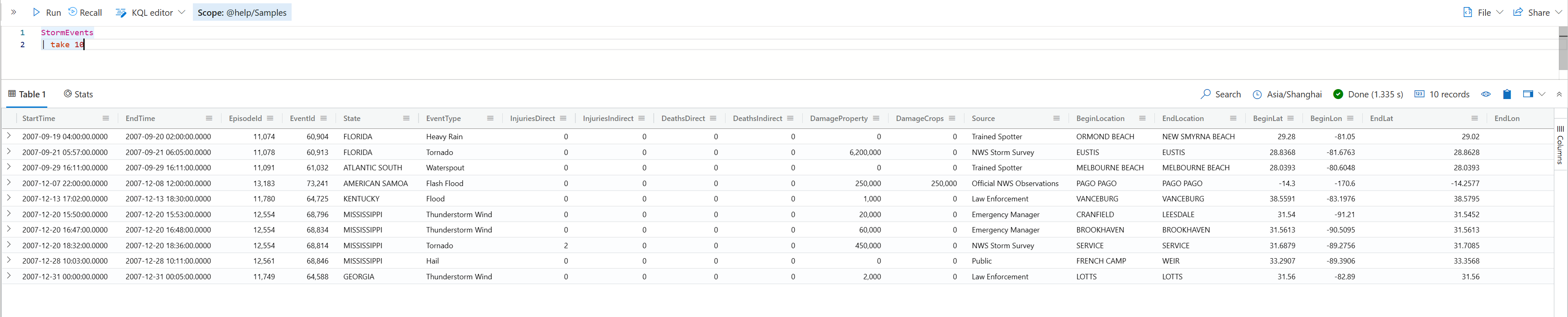
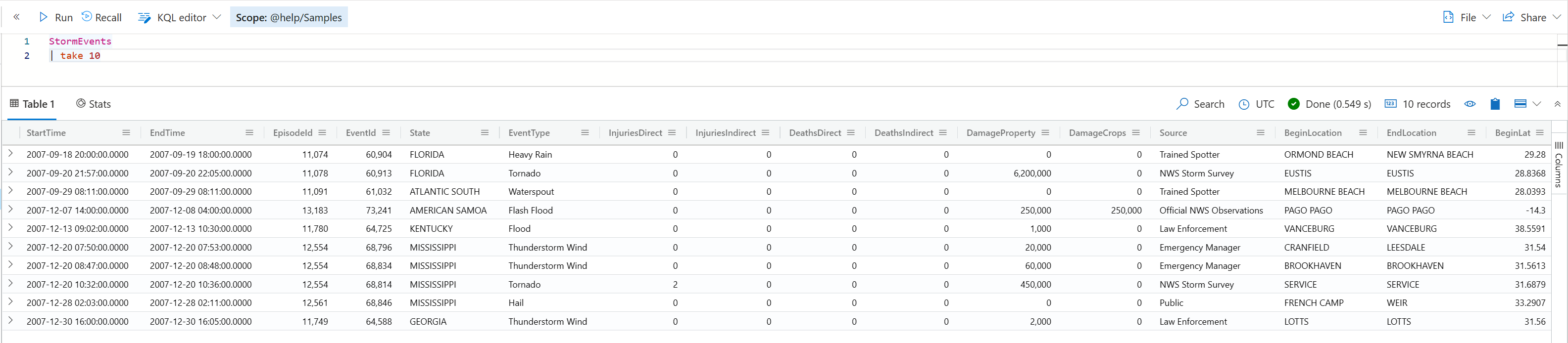
但是,如果你在同一个浏览器窗口,你可能发现多次运行的话,结果可能是一样的。这是因为当前这个session 会有缓存的原因。Kusto既然如此聪明,它不会笨到既然知道你只是为了取样,而每次都真的执行查询的。
如果结果集本身是排好序的,那么每次只会取最开始的指定行数,这是能得到一致的结果的。有兴趣你可以尝试一下
StormEvents | order by StartTime asc | take 10。
sample, rand
sample 跟 take的区别在于,它永远是随机返回指定的行数,而不是从头部开始取。请尝试在不同窗口执行 StormEvents | sample 10 。
除了指定一个精确的返回行数,我们可能有时候会想,能否给我返回差不多1%的数据吧。这个可以通过 rand 这个操作符来实现。
StormEvents | where rand() < 0.01
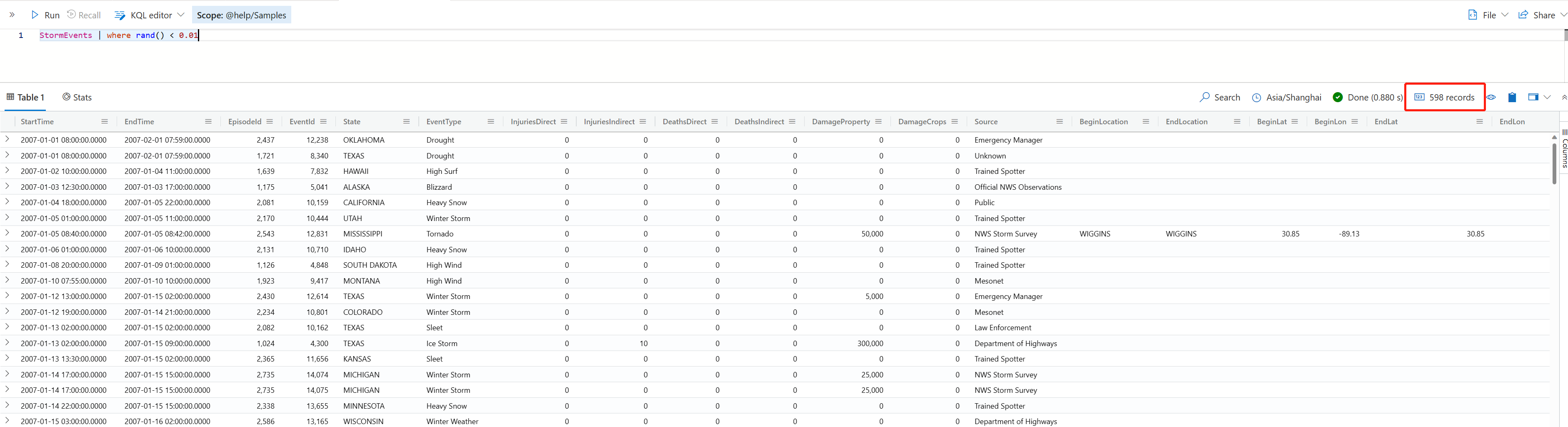
rand 这个操作符本身是用来产生一个随机数的,但这里的用法更妙。
distinct, sample-distinct
另外一个常见的探索数据的场景,就是我们想了解一下某个列具体有哪些可用的值。这个时候就可用 distinct 操作符了。你也可以指定多个列, distinct 将返回这多个列组合起来不重复的值。
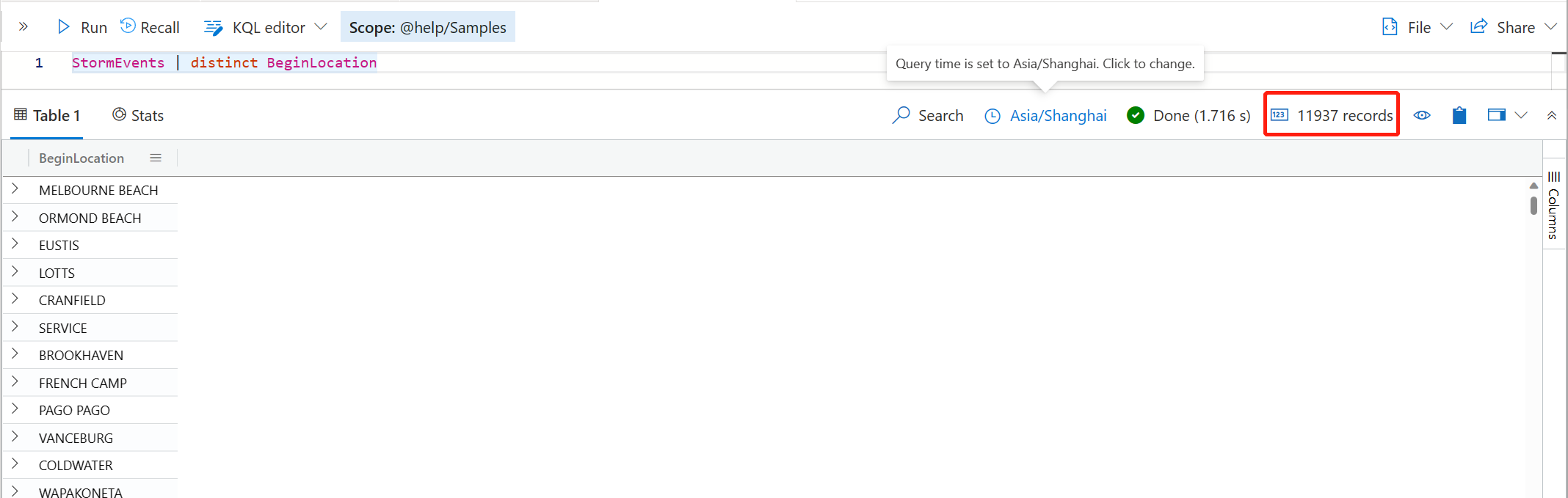
distinct 会返回所有的不重复值。那么,如果你想在其中随机挑选几个出来,就可以用 sample-distinct 了,请看下面的例子。
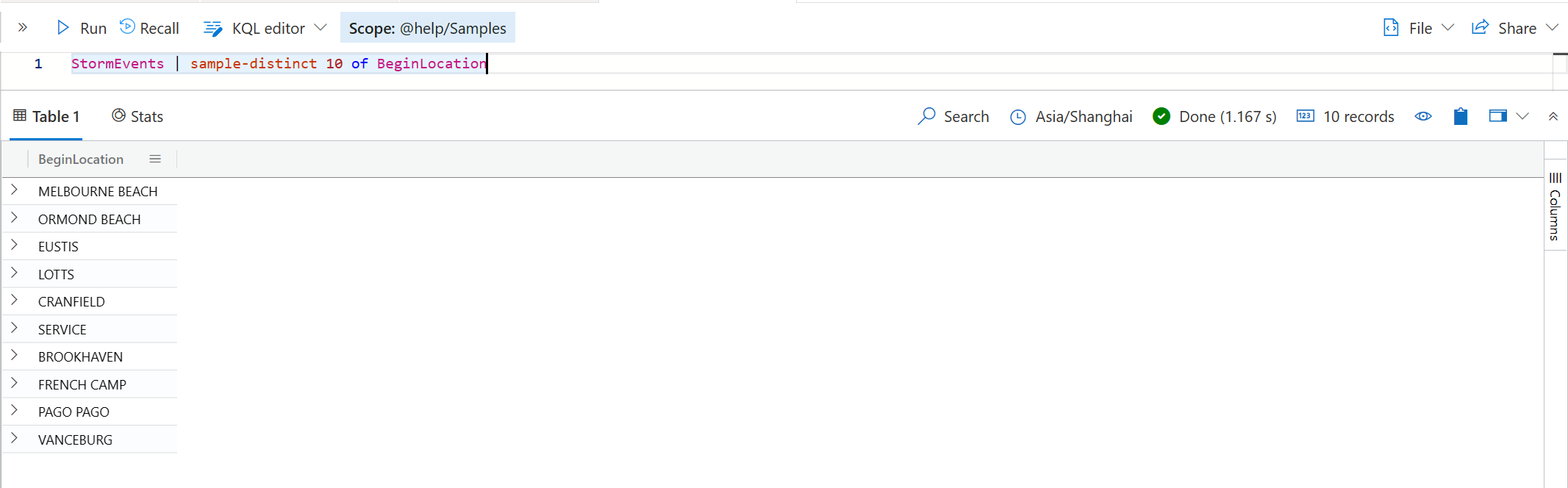
count, max, min
在进行数据探索时,我还经常希望了解某个字段的行数,最大值和最小值之类的。这时候会用到 count, max, min 这几个聚合函数。下面是一个简单的实例。
StormEvents | summarize count(), max(StartTime), min(StartTime)
数据的探索部分就到这里。下面我们从几个不同的角度来逐步展开数据查询的基本用法。
两个注意事项
开始之前,我希望你对 Kusto 的查询的两个注意事项有所了解,它们分别是:
- Kusto 文本是区分大小写的,也就是说, A 是不等于 a 的, 很可能这是为了提高性能而这么设计的。这个要有一个心理准备,如果希望忽略大小写的话,会有一些特殊的运算符。
- 例如 =~ (等于运算,且不区分大小写), 或 !~ (不等于运算,且不区分大小写) 等等。
- Kusto 中对于日期和时间处理,都是将其视作 UTC 时间的。这个在 [[第一章 - Kusto 简介#时区设置]] 小节有做了介绍,更改个人设置中是时区将改变显示效果,但不会改变数据本身。
- 有两个函数可以转换 UTC 时间和本地时间,它们是
datatime_utc_to_local和datetime_local_to_utc, 你可以在查询中真正需要时用它。
- 有两个函数可以转换 UTC 时间和本地时间,它们是
数据过滤和搜索
在数据查询中,首当其冲的就是对数据进行过滤或者搜索。因为Kusto 是一个大数据分析工具,所以你不可能每次都针对所有数据进行扫描或计算,那既不是明智,也不是有必要的。
这一节我们将分享如何用 where 和 search,find 操作符实现灵活筛选和搜索。
where, filter
如果要统计所有的Kusto 查询,我敢担保 where 这个操作符的使用率肯定是名列前茅的。它的基本用法可能大家也都很熟悉,在 where 后面跟上一个断言表达式(Predicate),如果该断言返回 true,则表示满足筛选条件。
📣 filter 是 where 的同义词。
值得注意的是,这个断言可以是一个,也可以是多个,而且多个断言之间可以用 and 或 or 组合起来。下面有几个实例。
// 只有一个断言的筛选
StormEvents
| where State == "UTAH"
// 有多个断言的筛选
StormEvents
| where DamageProperty > 0
and EventType == "Flood"
and BeginLocation != EndLocation
// 同样多个断言,但分开多个where语句,其实也相当于是 and 的效果
StormEvents
| where DamageProperty > 0
| where EventType == "Flood"
| where BeginLocation != EndLocation
// 有多个断言,但因为是 or 的关系,不能简单拆分为多个where 语句
StormEvents
| where State == 'UTAH' or DeathsDirect > 0
一般我们理解的断言表达式,都是由三个部分组成的,左侧是待检测的值(字段),中间是比较运算符,右侧是用来比较的值。但是 where 还有一个特殊的用法,就是左侧用 * 来表示所有字段,这就有点类似于全文检索了,请注意,这种情况只适合对文本字段进行比较。
📣本节后面还会讲到另外一个search操作符,也是实现类似功能。
StormEvents
| where * has 'UTAH'
不要太过于担心全文检索的性能,Kusto 对于文本的全文检索提供了优化。
在了解了 where 的基本结构后,你就会明白真正重要的是不同的数据类型支持不同的比较运算。下面针对主要的数据类型做一些展开说明。
日期比较运算
常见的日期比较无外乎就是以下两种
- 在(不在)某个时间段之内
- 大于或小于、(不)等于某个时间
第一种需求,用 between 和 !between 即可,而第二种需求,也是很直白地,用 >,>= ,<,<= ,== , != 即可。
但是这里重要的是,右侧用来比较的值,怎么表示成一个日期数据(datetime, date, time)?它涉及到一些很有意思的函数。
| 函数 | 作用 | 范例 |
|---|---|---|
| datetime | 将一个数值转换为日期 | datetime(1970-1-1), datetime('1970-1-1 20:00:04') |
| todatetime | 同上,推荐使用datetime | todattime(1970-1-1) |
| make_datetime | 输入年月日等参数来生成一个日期 | make_datetime(2001,1,1) |
| ago | 过去的一个日期或时间 | ago(1d) 表示昨天, ago(1h) 表示过去一小时, ago(-1d) 表示明天 |
| now | 现在或未来的日期或时间 | now() 表示现在, now(2d) 表示后天, now(-1d) 表示昨天 |
我们有些日志文件中,保存的日期时间是一种所谓的 unixtime,它看起来是一串数字,通常是指从 1970年1月1日的零点到现在的秒数,例如 1546897531 ,那么怎么把这样一个数值转换为日期类型呢?你可以使用 unixtime_seconds_todatetime 函数,例如 print date_time = unixtime_seconds_todatetime(1546897531)。
如果要把一个日期转换为 unixtime,则可以使用 (datetime(2023-1-2)-datetime(1970-1-1))/1s, 得到的结果为 1672617600。
我们再来看一下 between 的用法,通常情况下,它的参数为两个日期时间值,例如
StormEvents
| where StartTime between (datetime(2007-1-1) ..datetime(2007-2-1))
但也还有一个写法,第二个参数可以是一个 timespan 的语法,上面提到的 1d, 1h 其实都是所谓的timespan 的语法。
StormEvents
| where StartTime between (datetime(2007-1-1) ..1d)
文本比较运算
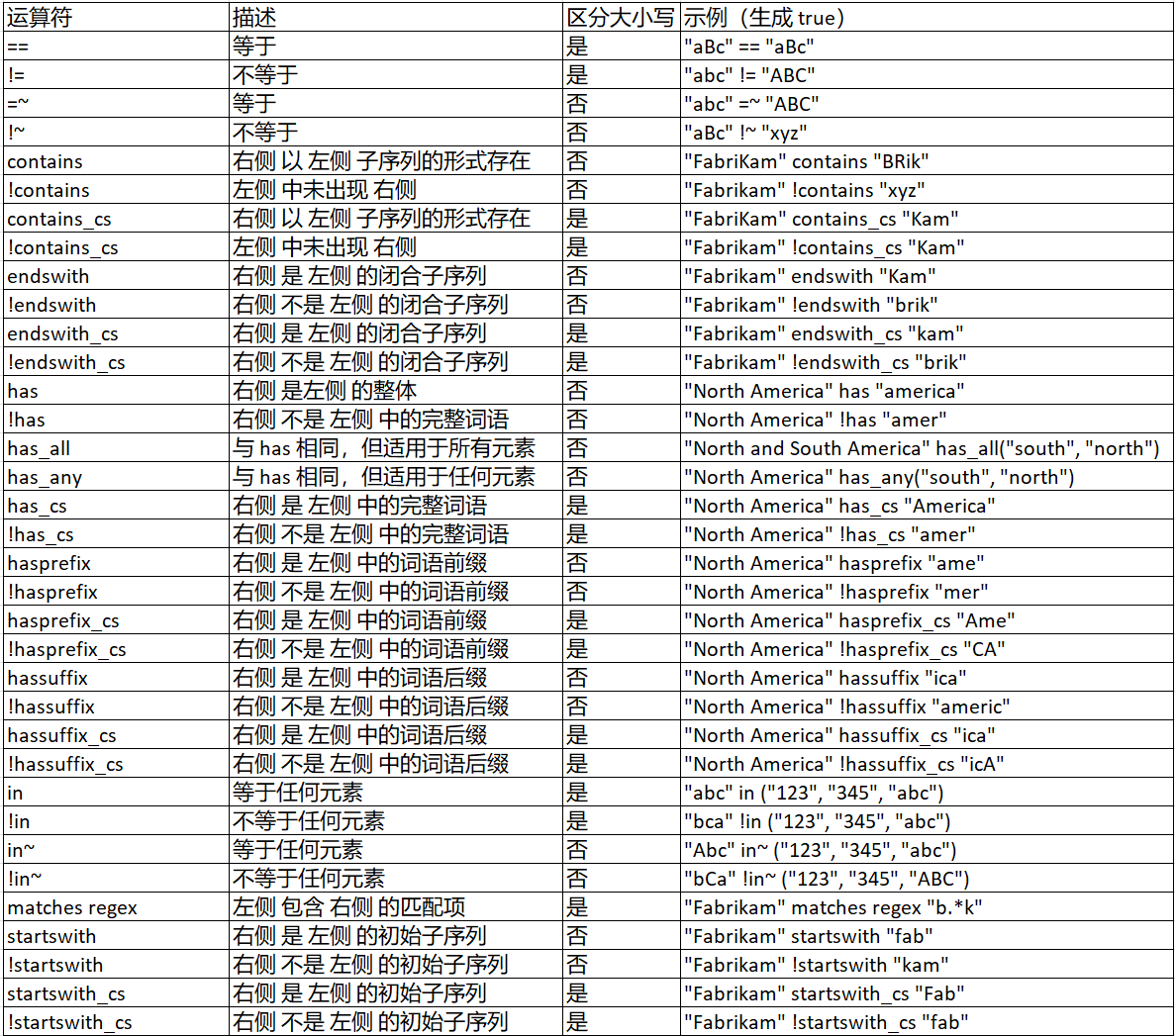
文本的比较运算在 Kusto 中是非常丰富的,下面有一个完整的表格。我最常用的有 == , has 这两个,但其实每一个都值得了解一下。
请注意,带有 ~ 后缀的运算符是不区分大小写的,而带有 _cs 后缀的,则是区分大小写的。
在Kusto查询中,你可以用两个单引号(') 定义一个字符串,也可以用两个双引号("),本质上没有区别。这个在很多编程语言也是如此设计。我习惯用单引号,因为这样输入更快一点,你不需要按住 Shift 键来输入双引号。另外,在单引号定义的字符串中,可以有双引号,反之亦然。
数值比较运算
数值比较运算相对简单,事实上它跟日期很类似,可以用 between 和 !between 来判断是否在一个连续的范围,也可以直白地,用 >,>= ,<,<= ,== , != 即可,当然还可以用 in, !in 来比较是否在一个不连续的列表值中。
性能建议
有几条一般性的建议,可以用来提升筛选数据的性能
尽量不要在比较运算符的两侧还有值计算的表达式。最理想的查询是左侧为字段名,右侧为一个常量。例如
where State == 'UTAH'。如果确实涉及到运算,可以考虑用let语句定义它,然后在where子句中引用这个变量。let avgDeaths = toscalar (StormEvents | summarize avg( DeathsDirect)); StormEvents | where DeathsDirect > avgDeaths这要比下面这样的查询好得多。
StormEvents | where DeathsDirect > toscalar (StormEvents | summarize avg( DeathsDirect))按复杂性从低到高进行筛选排序。例如下面的查询,有三个条件,通常数值型复杂性会小于文本型,而最后那个是更复杂,因为两侧都没有常量。
StormEvents | where DamageProperty > 0 and EventType == "Flood" and BeginLocation != EndLocation过滤行数更多的条件放在前面。如果有时间过滤的条件,尽可能放在最前面,因为Kusto 针对时间有专门的优化。
search
search 是一个神奇的操作符,它基本上就相当于 Kusto 版本的全文检索引擎吧。它可以在整个表(甚至整个数据库中)搜索文本,支持通配符,也支持大小写敏感。
有两种常见的用法,分别是
- 以表为起点,作为类似
where的操作符进行使用,搜索发生在当前表的范围之内。 - 直接作为顶级语句,可以在数据库,或者指定表中搜索。
以表为起点搜索
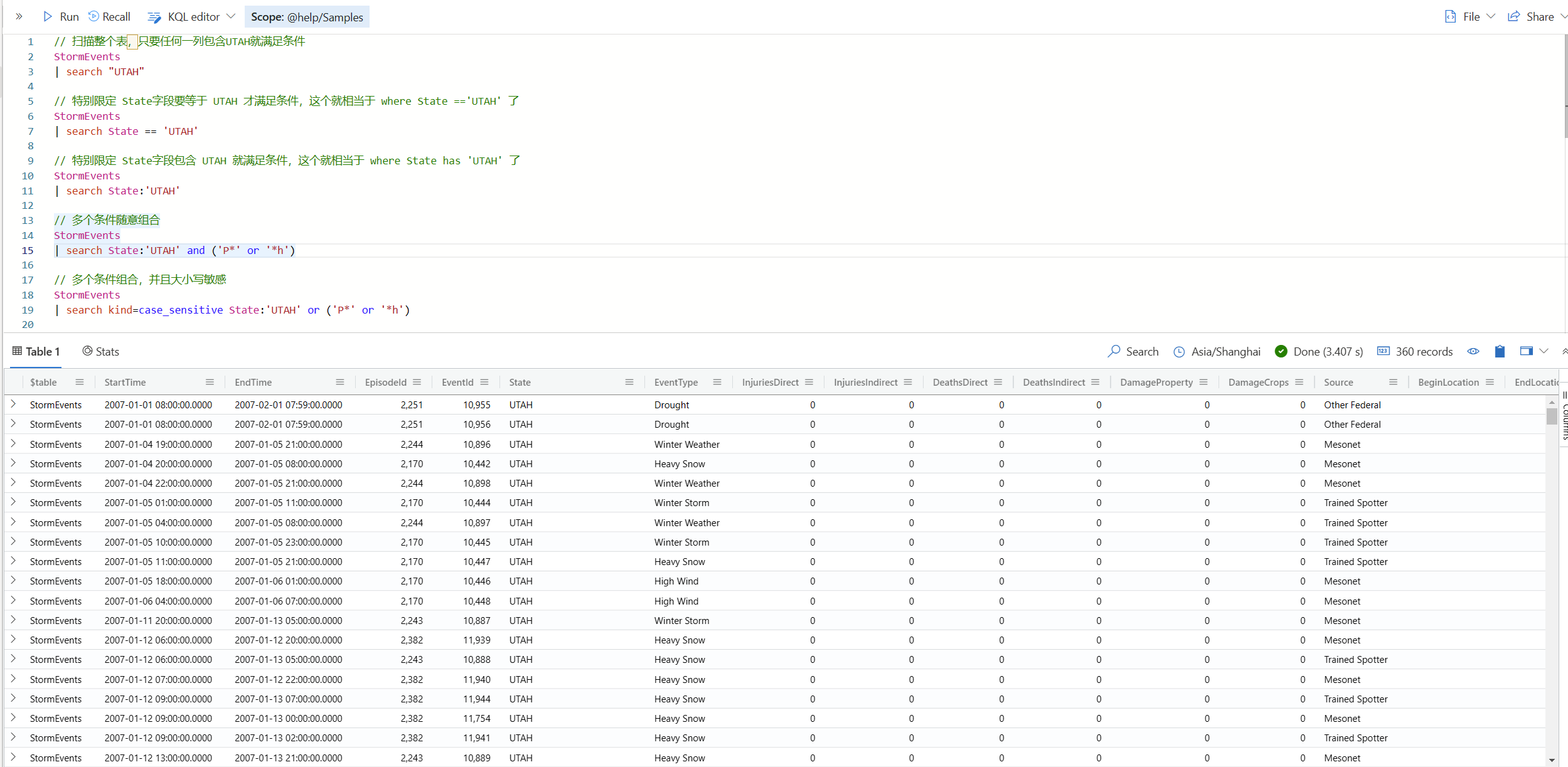
// 扫描整个表,只要任何一列包含UTAH就满足条件
StormEvents
| search "UTAH"
// 特别限定 State字段要等于 UTAH 才满足条件,这个就相当于 where State =='UTAH' 了
StormEvents
| search State == 'UTAH'
// 特别限定 State字段包含 UTAH 就满足条件,这个就相当于 where State has 'UTAH' 了
StormEvents
| search State:'UTAH'
// 多个条件随意组合
StormEvents
| search State:'UTAH' and ('P*' or '*h')
// 多个条件组合,并且大小写敏感
StormEvents
| search kind=case_sensitive State:'UTAH' or ('P*' or '*h')
这个结果集会多出来一个字段, $table 显示表的名称。
自由搜索
这种搜索就更牛了。它甚至可以在整个数据库中随便搜索,当然也可以指定多个表。不过,据我观察,速度可能会比较慢,慎重使用。
// 在整个数据库中所有表中搜索 包含 UTAH 的记录
search 'UTAH'
// 在指定的一个或多个表中搜索 包含UTAH的记录
search in ( StormEvents, ConferenceSessions) 'UTAH'
// 在指定的 StormEvents 以及C开头的表中搜索包含UTAH的记录
search in ( StormEvents, C*) 'UTAH'
// 在指定的 StormEvents 以及C开头的表中搜索包含UTAH 和以P字符开头的记录
search in ( StormEvents, C*) 'UTAH' and 'P*'
如果涉及到多表查询,返回的结果集会把多个表的字段都合并起来,形成一个很大的合集。并且第一个字段同样为 $table ,也就是表的名称。

find
这个更有意思。它很像 search 的第二种用法,不过它的返回值不一样。
当前数据库查找
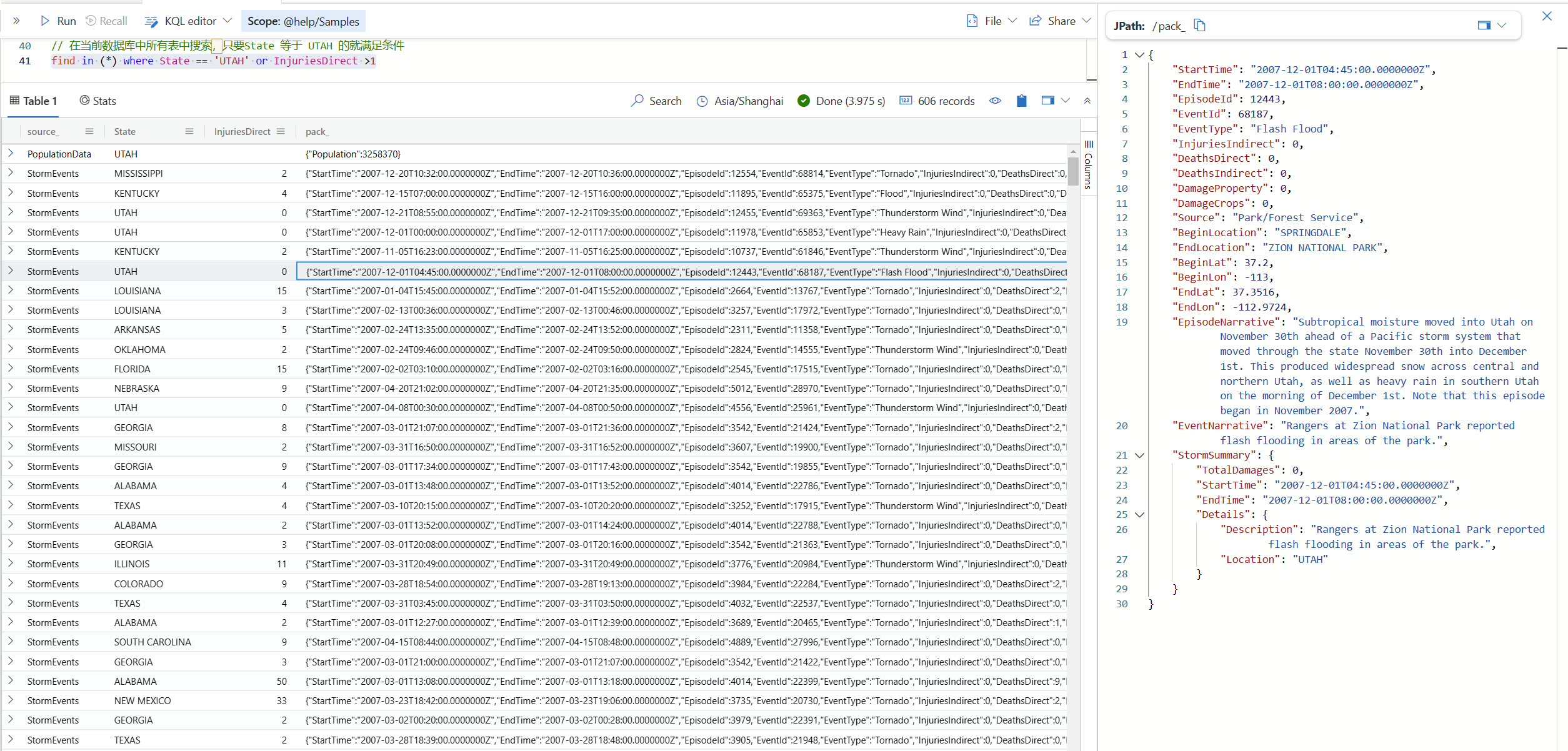
find in (*) where State == 'UTAH' or InjuriesDirect >1
find的结果集除了会列出条件列(例如上面的 State 和 InjuriesDirect)之外,还有两个列,source 表示来源表,而 pack 则表示符合条件的行的一个打包的结果,它会用一个 json 格式表示。这个在Kusto 中其实叫做 dynamic 数据类型。
跨数据库查找
它还可以跨数据库(用database关键字),跨群集(用 cluster关键字)进行搜索。额的神啊,Kusto 你咋不上天呢?下面是一些简单的
find in (Table1, Table2, Table3) where Fruit=="apple"
find in (database('*').*) where Fruit == "apple"
find in (cluster('cluster_name').database('MyDB*'.*)) where Fruit == "apple"
find in (cluster("cluster1").database("B*").K*, cluster("cluster2").database("C*".*))
where * has "Kusto"
选择或扩展字段
如果说筛选和过滤、或者搜索一般都是 Kusto 查询的第一步,那么接下来我们通常就会对要返回的列进行选择,或者在这个结果集基础上扩展出新的字段。
选择字段 - project
如果你对传统的数据库查询有些概念,对 where 这个子句肯定不会陌生,然后这一小节要讲的选择字段,其实相当于以前的 select 子句,只不过 Kusto 用 project 这个操作符。
project 在这里不是指 项目 的意思,而是 投射 的意思,工作中我们如果要把电脑画面投到一个屏幕上,也会用 project 这个动词。
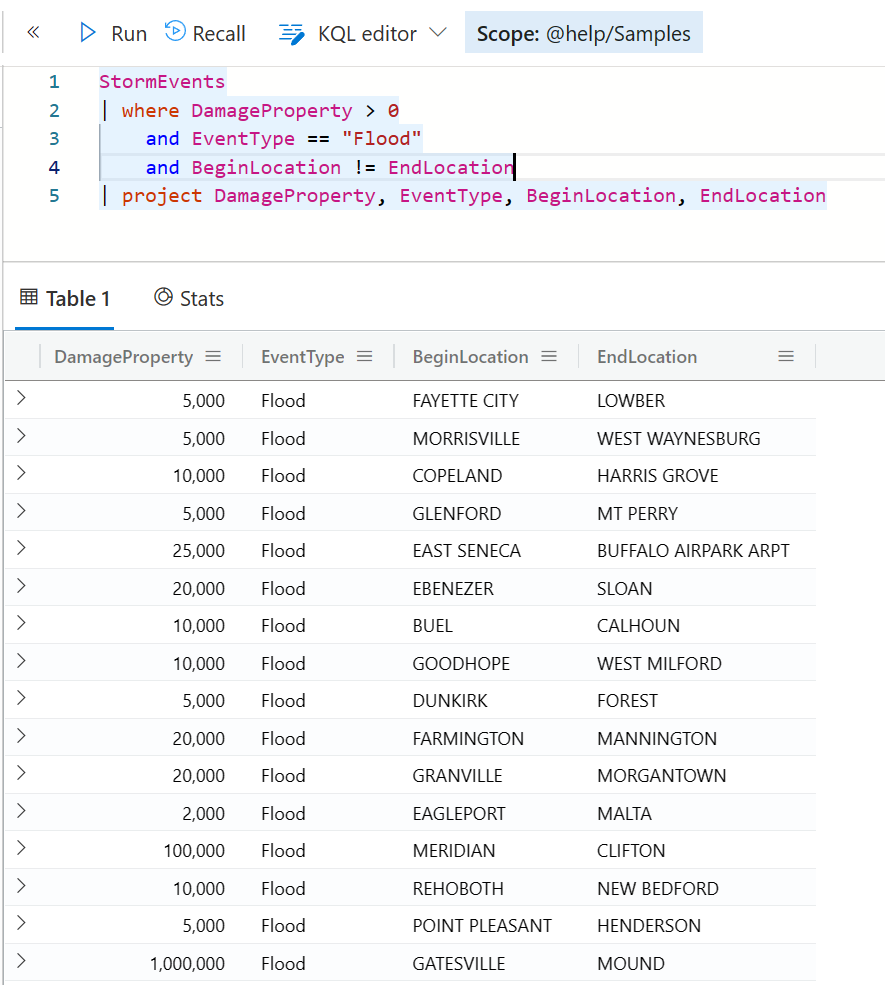
StormEvents
| where DamageProperty > 0
and EventType == "Flood"
and BeginLocation != EndLocation
| project DamageProperty, EventType, BeginLocation, EndLocation
在投射的过程中,你可以对列进行重命名,例如下面这样。
StormEvents
| where DamageProperty > 0
and EventType == "Flood"
and BeginLocation != EndLocation
| project ['Damage Property'] = DamageProperty, EventType, BeginLocation, EndLocation
还有一个更加学院派的写法,就是使用 project-rename 操作符。
StormEvents
| where DamageProperty > 0
and EventType == "Flood"
and BeginLocation != EndLocation
| project DamageProperty, EventType, BeginLocation, EndLocation
| project-rename ['Damage Property'] = DamageProperty
效果其实是一样,所以让 project 就干投射的工作,也许更好一些。
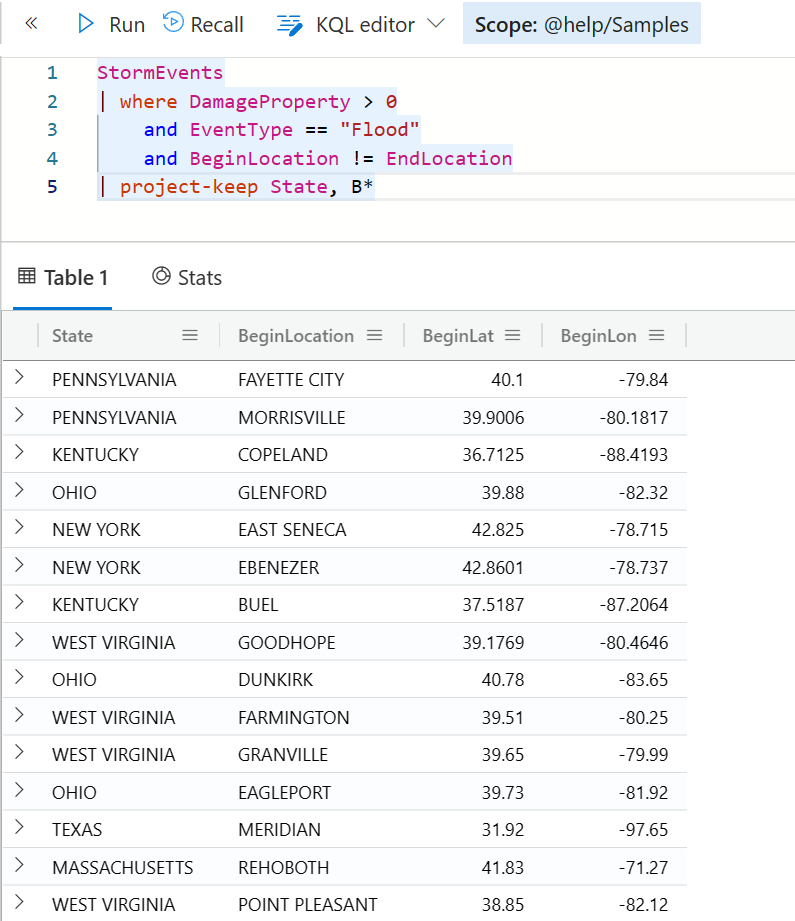
如果你要一次性 project 多个字段,但又不想一个一个字段地列出来,你可以用 project-keep 这个操作符, 它既可以指定明确的字段名,也可以通过一个范式表示一批字段,例如下面例子只保留 State 和以 B 开头的字段。
StormEvents
| where DamageProperty > 0
and EventType == "Flood"
and BeginLocation != EndLocation
| project-keep State, B*
反过来,如果你想排除一些列,则可以用 project-away 这个操作符。
StormEvents
| where DamageProperty > 0
and EventType == "Flood"
and BeginLocation != EndLocation
| project-away State, B*
project 家族甚至还有一个可以对输出列进行排序的操作符,叫 project-reorder。下面这个例子,是把 State 字段排在第一个,然后其他的字段,以字母升序排列。
StormEvents
| where DamageProperty > 0
and EventType == "Flood"
and BeginLocation != EndLocation
| project-reorder State,* asc
这里的排序规则有 升序 asc, 降序 desc , 复古升序 granny-asc, 复古降序 granny-desc 四种。复古这个翻译是我自己想出来的,其实 granny 的意思是指它在排序时还会考虑名称中的数字部分。例如,如果你想让 a100 这个字段,出现在 a20 之后,那么就要用 granny-asc (因为100>20), 如果你用标准的 asc ,它会尝试用字符进行比较,所以 a100 会出现在 a20 之前,因为 1<2。
扩展字段 - extend
有时候,我们在结果集中希望添加自己的计算字段。这种行为其实叫做扩展字段,而在Kusto 中就是用 extend 这个操作符来实现的。我们都知道 extend 就是扩展的意思,所以我在序言中提到过,Kusto 之所以跟以前的查询不一样,是因为它的语法非常直观,符合直觉,也跟英语的口语很像,所以你在写一个查询,就好像在说话一样。
StormEvents
| where DamageProperty > 0
and EventType == "Flood"
and BeginLocation != EndLocation
| extend TotalDamage = DamageCrops + DamageProperty
这个查询会在原有结果集的基础上,在最后面添加一个新的列叫做 TotalDamage ,而它的值是一个运算的结果。
extend 操作符可以一次性扩展多个列,只要用逗号分开即可。
其实,前面讲到的 project 也可以用来添加一个新的列,并且赋予它一个运算的结果。
StormEvents
| where DamageProperty > 0
and EventType == "Flood"
and BeginLocation != EndLocation
| project TotalDamage = DamageCrops + DamageProperty
但由于 project 的语义是 投射, 而不是扩展或者追加,所以上面这个查询,只会返回一个列,而不是所有列 + 这个新的列。
我展示这个例子,只是告诉大家很多操作符也许能做类似的事情,但本质上他们还是有些细微差别的,只有你深刻了解了它的语义,灵活运用它才能融汇贯通。
条件计算 - case
此前的例子已经看出,在 project 和 extend 过程中,可以实现计算字段,这当然就包含了加减乘除,以及还有很多的函数。这里不做逐一的讲解,但我想介绍一个最常用的条件计算的函数 case。
StormEvents
| where DamageProperty > 0
and EventType == "Flood"
and BeginLocation != EndLocation
| project
State,
StartTime,
EndTime,
Level = case(
DamageCrops > 1000,
'High',
DamageCrops > 500,
'Medium',
'Low'
)
case 可以根据一个(或多个)表达式进行运算,然后匹配不同的值,如果全部没有匹配到,则返回最后的那个值(也称为默认值),这个设计很像很多编程语言中的 switch 语句。
如果你的条件计算比较简单,例如只是非此即彼的二分法 (if this then that) ,你除了用 case 还可以用 iff 函数。
StormEvents
| where DamageProperty > 0
and EventType == "Flood"
and BeginLocation != EndLocation
| project
State,
StartTime,
EndTime,
Level = iff(DamageCrops > 1000, 'High', 'Normal')
汇总统计分析
到现在为止,我们研究了如何对源数据进行筛选和过滤,然后进行字段选择或者扩展,以便仅输出我们需要的字段(这有助于提高性能),但这样的结果其实还是原始数据,对于大数据分析来说,当然不会满足于此,我们接下来就要对齐进行汇总统计分析,这就需要用到 summarize 了。
汇总统计 - summarize
下面这个查询是一个最简单的例子。 summarize 操作符的基本语法结构就是,指定要汇总的表达式(通常是一个聚合函数), 然后指定要按什么进行分类汇总(通常是一个字段,或多个字段,也可以是一个计算结果)。当然,正如你看到的,你可以重命名要返回的列的标题。
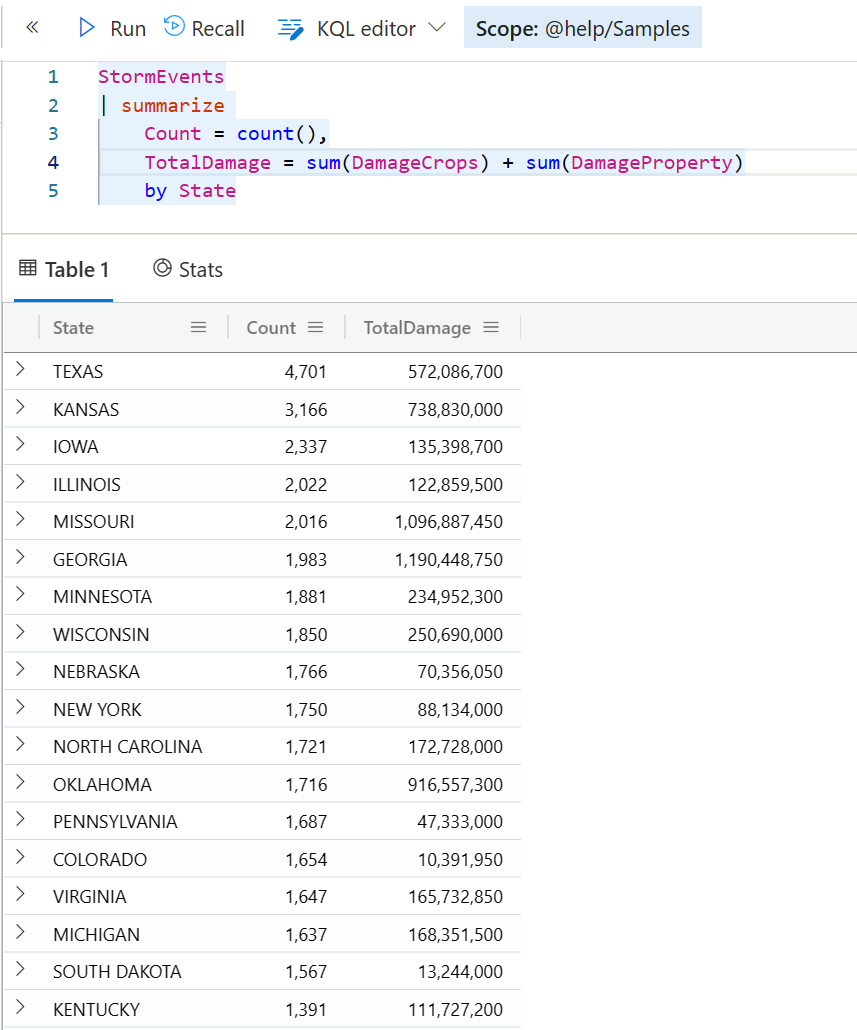
StormEvents
| summarize
Count = count(),
TotalDamage = sum(DamageCrops) + sum(DamageProperty)
by State
运行此查询可以得到每个州的暴风雨发生的次数,以及总的财产损失数量,不管是农作物还是财产损失。
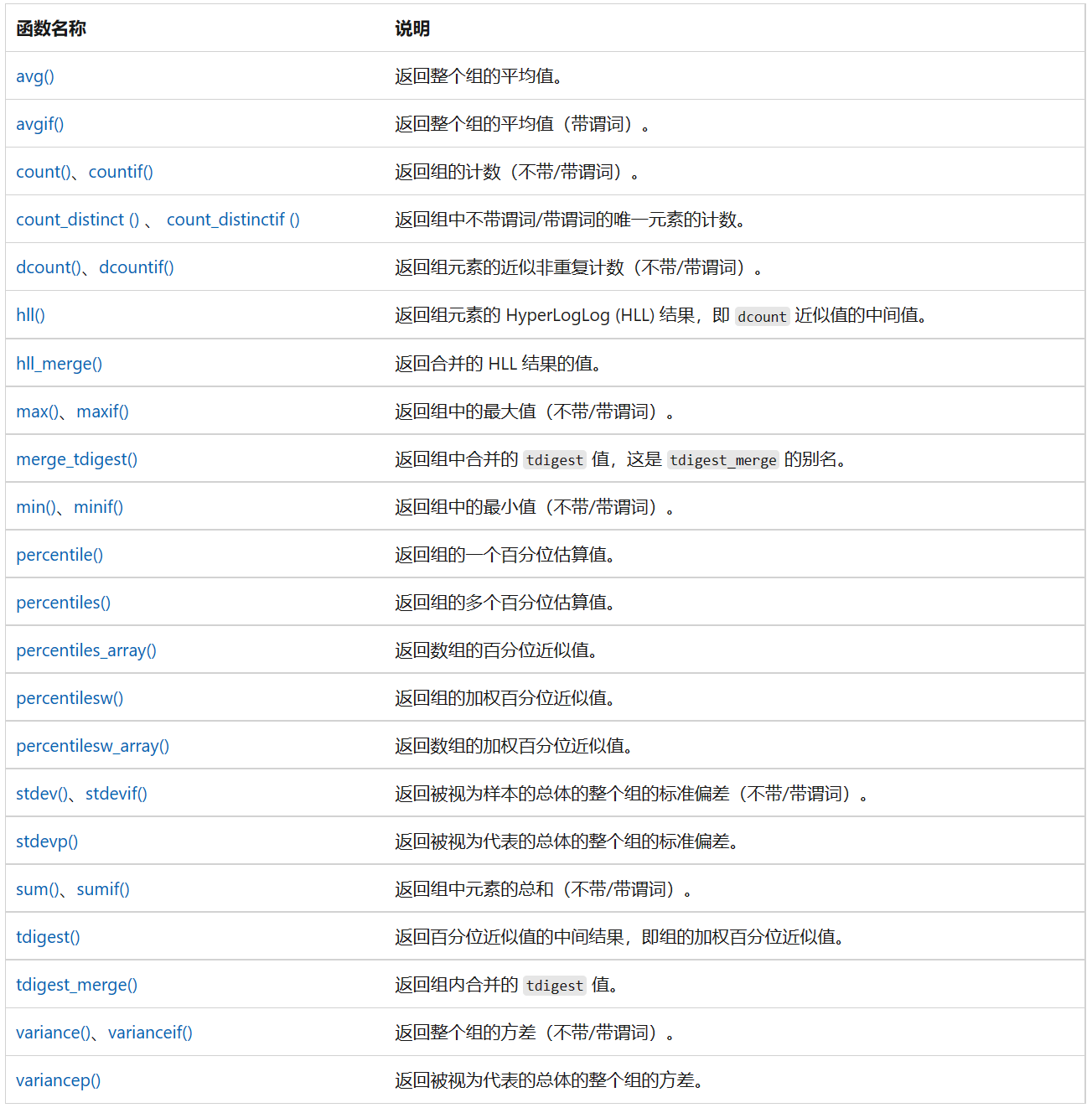
这里的关键是熟练掌握各种聚合函数,下表列出了所有的统计聚合函数,也是我们用的最多的。
在这里我专门介绍一个在业务分析中很有用的一个统计函数,percentile ,它用来返回一组数据的百分位估计值。
percentile, percentiles
例如我们有一批数据,表示每个暴风雨带来的损失。而我们想要知道,大部分的案例有多少损失。具体来说,例如我们想问,90% 的案例是多少损失以下呢?这在业务分析中就是要计算 P90 。
StormEvents
| summarize percentile(DamageCrops,90) by State
通过调整第二个参数值,你还可以得到P50, P75, P99等,只要你愿意都可以。
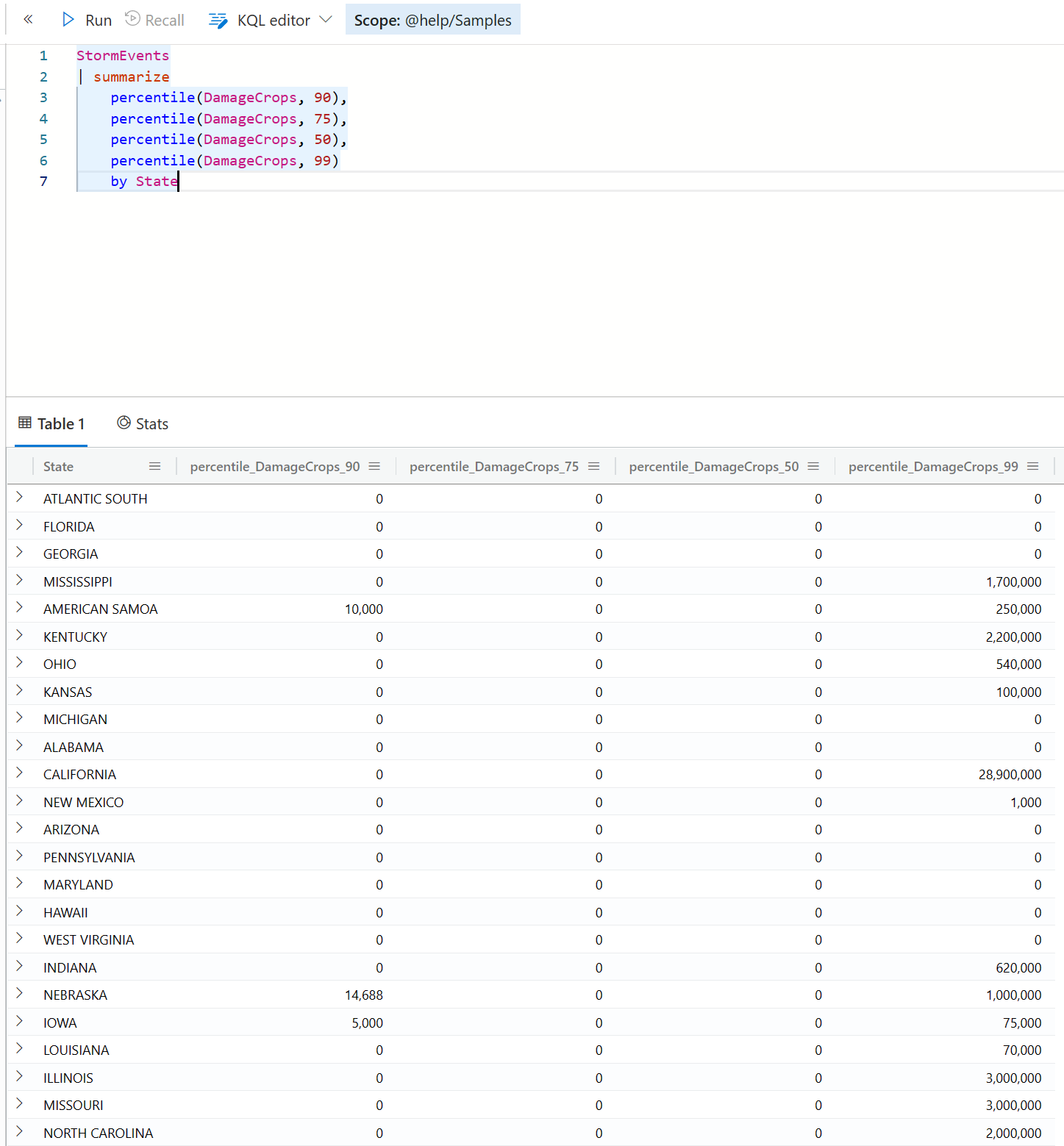
当然,如果你真的是想一次性计算多个 percentile,你可以直接用 percentiles 这个聚合函数即可。
StormEvents
| summarize
percentiles(DamageCrops, 50, 75, 95, 99)
by State
这类函数在估算网络延时(latency)或者吞吐量(throughput)时特别有用,当然它本质上是可以用在任意数据上面的,你可以通过它快速了解这些数据的分散情况。
关于聚合函数的更多细节,可以参考 https://learn.microsoft.com/en-us/azure/data-explorer/kusto/query/aggregation-functions 。
使用 bin 进行分组(分桶)
在汇总统计分析中,第一重要的部分是聚合函数,第二重要的部分就是分组表达式了。之前的例子中,我们都是直接用某个字段来作为分组的。但也有其他一些场景,我们希望对目标字段进行进一步分组,例如如果是一个时间字段,我们可能希望按照小时聚合,或者天,周等等。在Kusto中,这可以通过 bin 函数来实现,它就是分桶的概念。
这个分组尤其适合于 数值型 (int, long, real, decimal),日期型(date, time, datetime),时间段 (timespan)类型的字段。
StormEvents
| summarize
count() by bin( StartTime, 1d)
这个例子是以 StartTime 这个字段 ,按照每天进行聚合,统计发生暴风雨的次数。
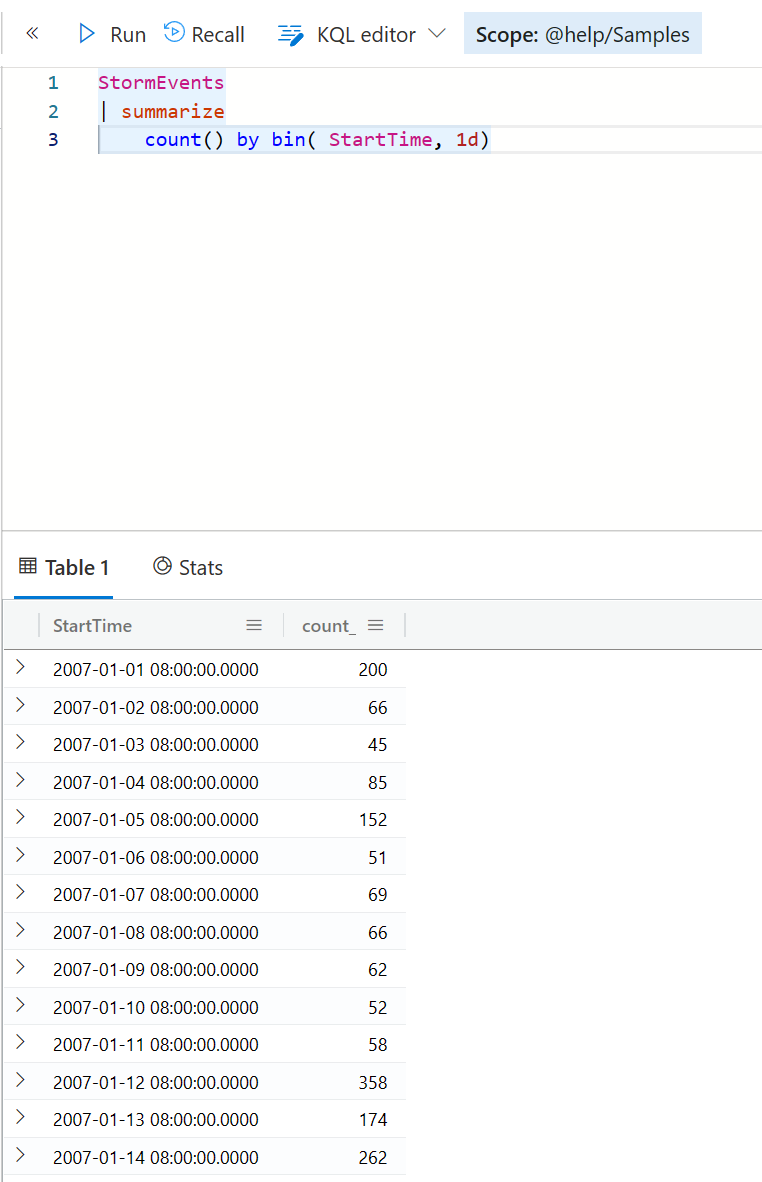
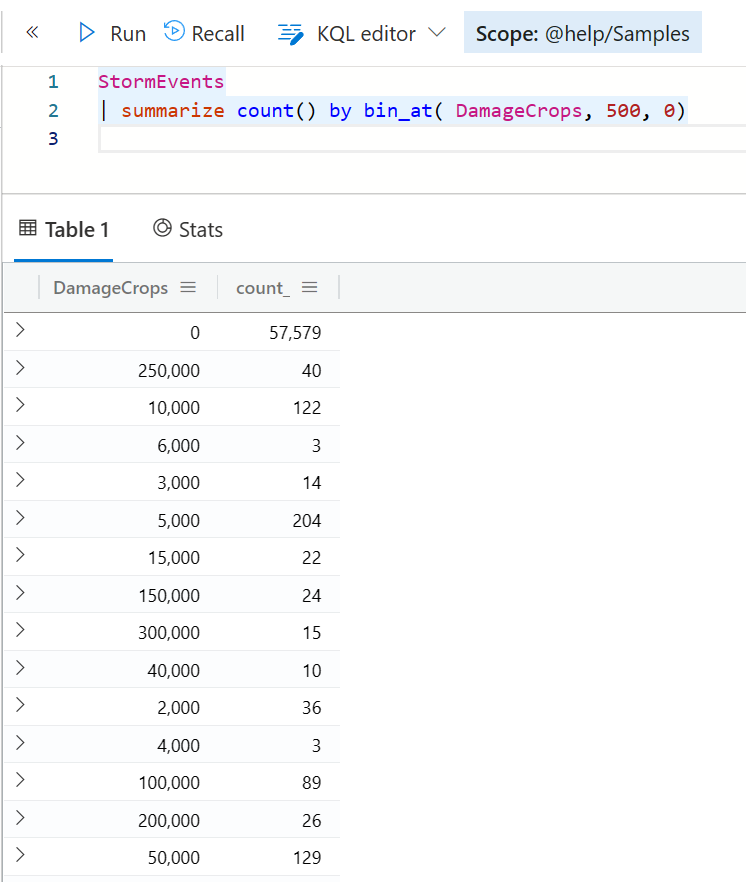
针对非日期数据,另外两个函数可能也比较有用。 他们是 bin_at 固定大小分桶,以及 bin_auto 自动分桶。
bin_at 是规定每个桶里面可以有多少个值,然后再按照这些值进行分类汇总。例如
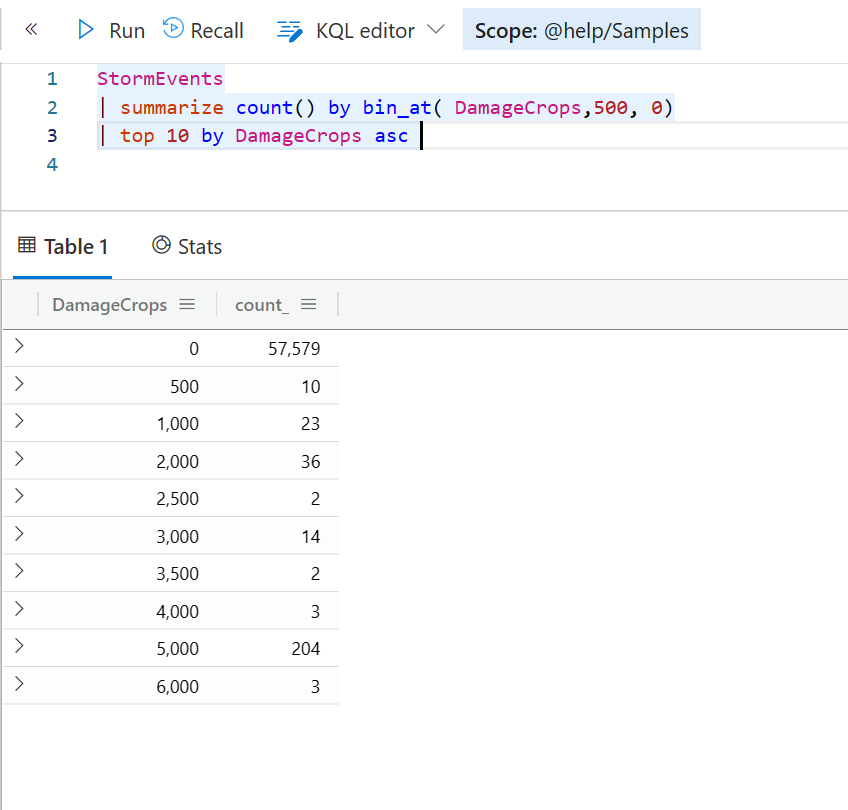
StormEvents
| summarize count() by bin_at( DamageCrops, 500, 0)
而 bin_auto 可能就是 bin_at 的一个特殊版本吧。它通过在查询之前设置一个环境变量来实现自动分桶,这样在每次执行 bin_auto 时就不需要单独再指定了。
set query_bin_auto_size = 10;
StormEvents
| summarize count() by bin_auto(DamageCrops)
排序
在前面介绍 bin_at 这个函数时,你可能发现返回的结果中, DamageCrops 是没有排序的,显得比较乱,也不利于后续的图表展示。如果是下面这样就会好很多。
sort, order
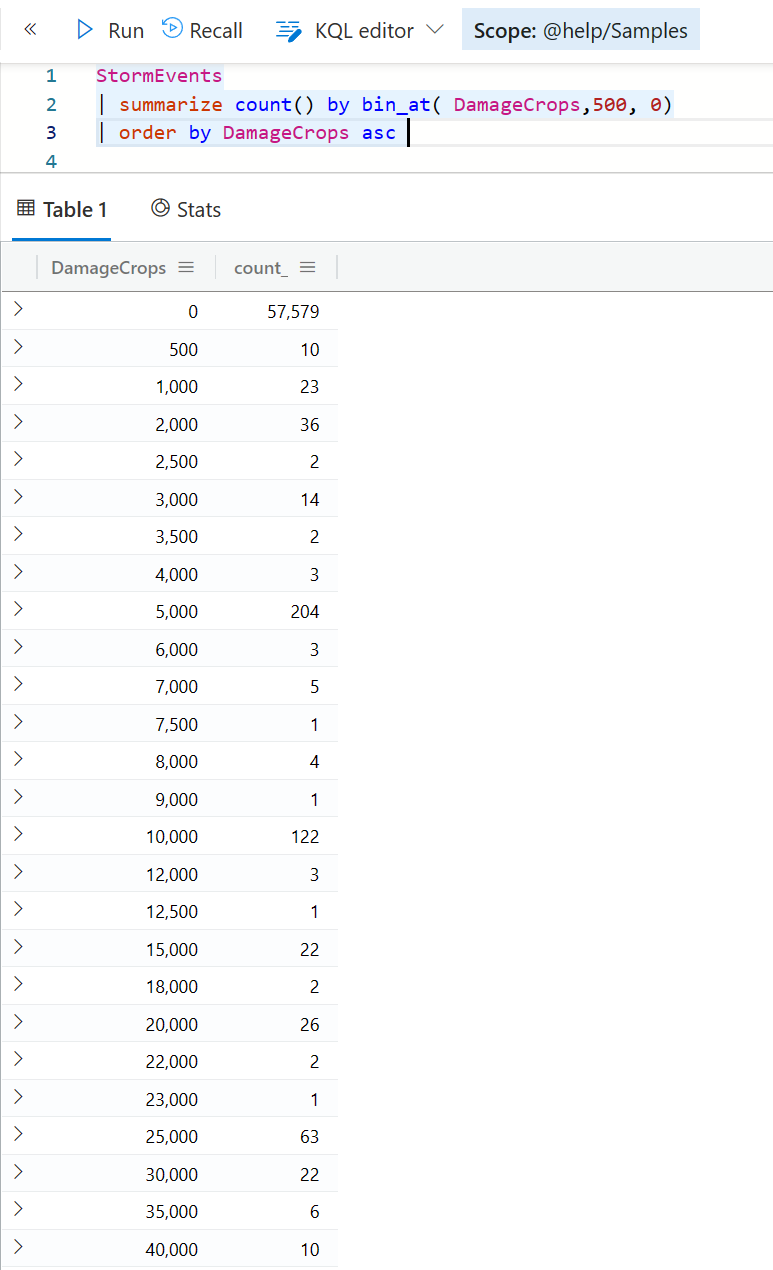
所以,在 Kusto 查询中,你经常也会用到排序操作符,他们就是 sort 或 order 操作符。你可以针对一个或者多个字段进行排序,排序规则有 asc 和 desc , 如果该列有空值,你还可以通过 nulls first 还是 nulls last 来决定空值是显示在最前面呢,还是在最后面。
top,top-nested
我们一般排序后有可能还需要显示前几名,这个时候你当然可以使用类似下面的语法 —— 结合 order 和 take 来获取前十个数据。
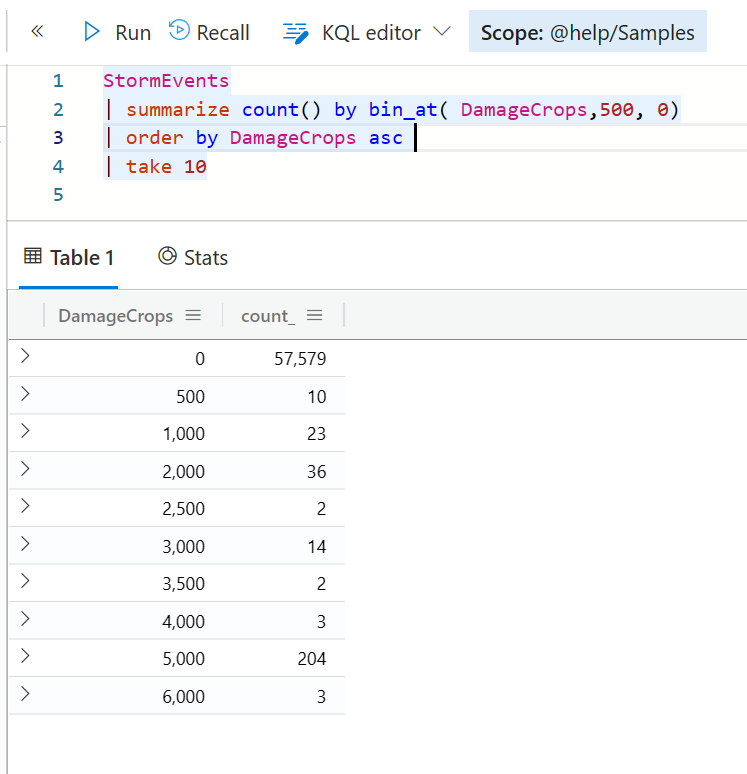
但是你也可以更加简单地使用 top 语句来实现同样的目的。
还有一种你可能很想实现的场景,例如你想知道在造成损失最大的前三个州中, 发生的次数最多的前十个暴风雨类型是什么呢?
StormEvents
| top-nested 3 of State by sum(DamageCrops) + sum(DamageProperty),
top-nested 10 of EventType by count()
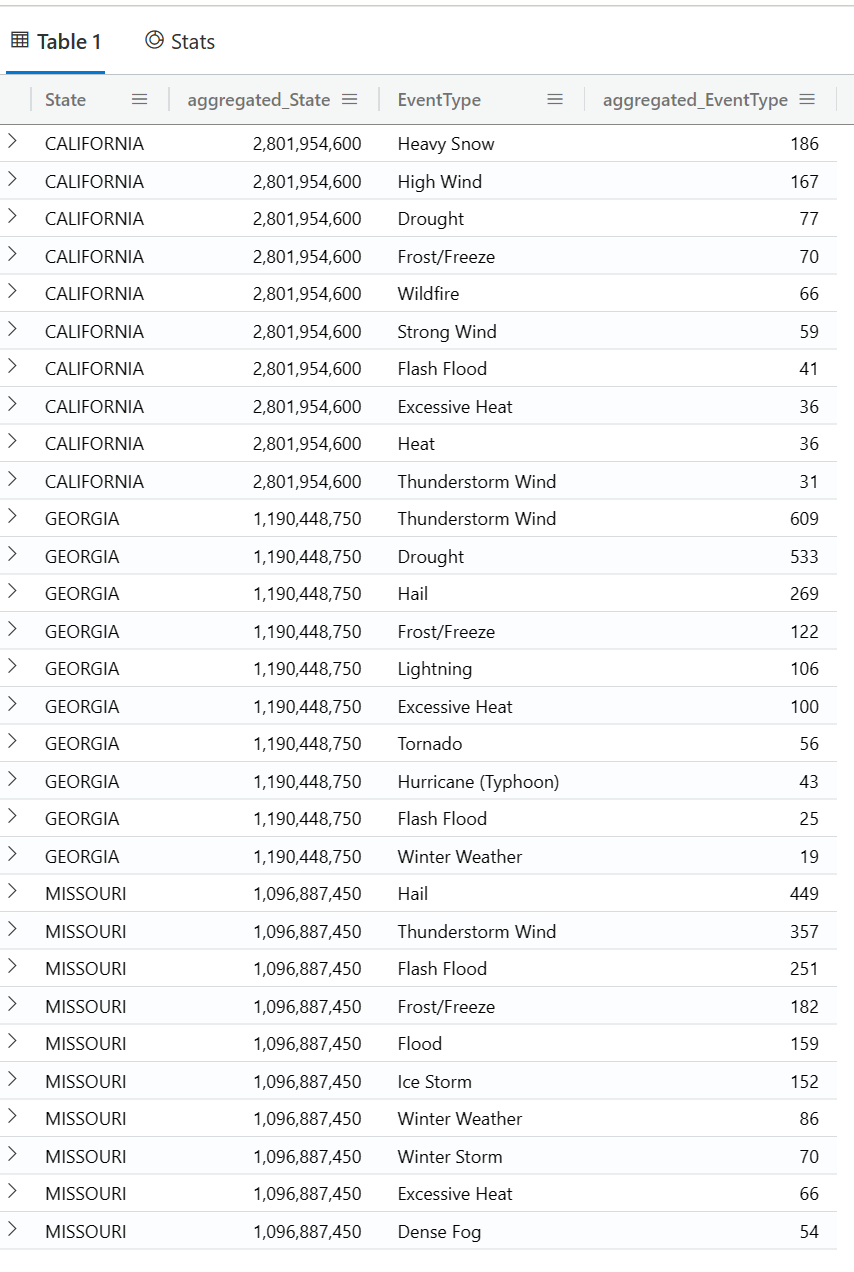
不可思议,难以置信吧,你可以写任意多层嵌套呢,只要你能看懂就行。
多表查询
到目前为止,我们写过的这么多查询大多都只是针对一个表,尤其是绝大部分都是针对 StormEvents 这个表进行操作。但实际情况,你几乎一定会用到多个表的数据,不管是在多个表中进行联合查找,还是合并多个查询结果集。
为了实现多表查询,你需要用到 join 或 lookup,为了实现结果集合并,你需要用到 union。
join, lookup
在我们的范例数据库中,StormEvents 这个表保存了每个州发生的暴风雨案例的数据,另外有一张表 PopulationData 则保存了每个州的人口数量。
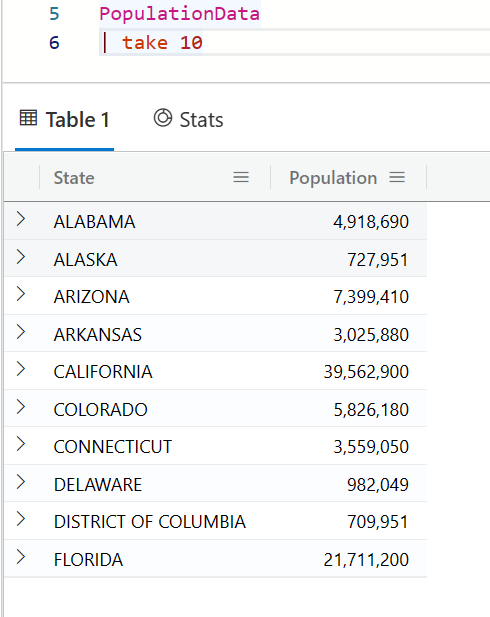
那么,我现在要用一个查询,统计每个州的暴风雨的次数,并且也想要同时显示它的人口数量。这就需要将两个表的数据通过州(State)这个字段连接起来,而且还要把结果集合并起来(横向的)。
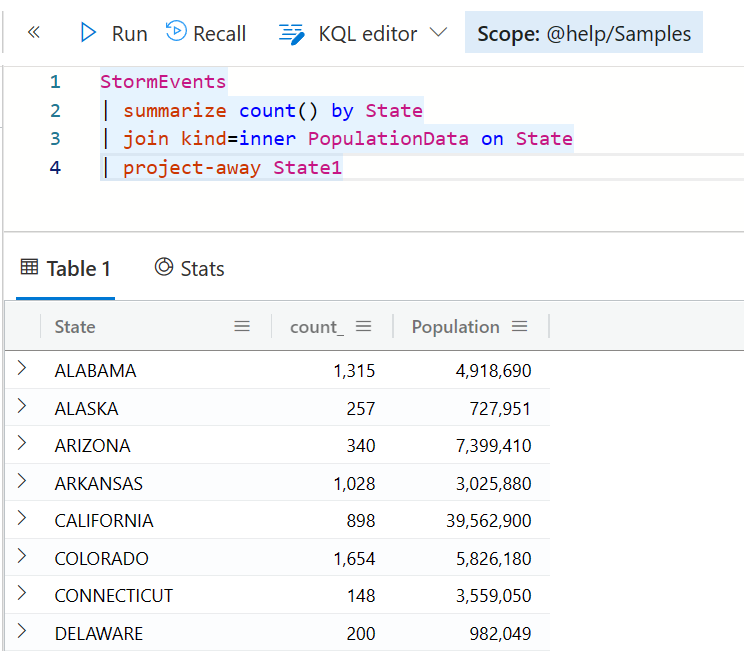
StormEvents
| summarize count() by State
| join kind=inner PopulationData on State
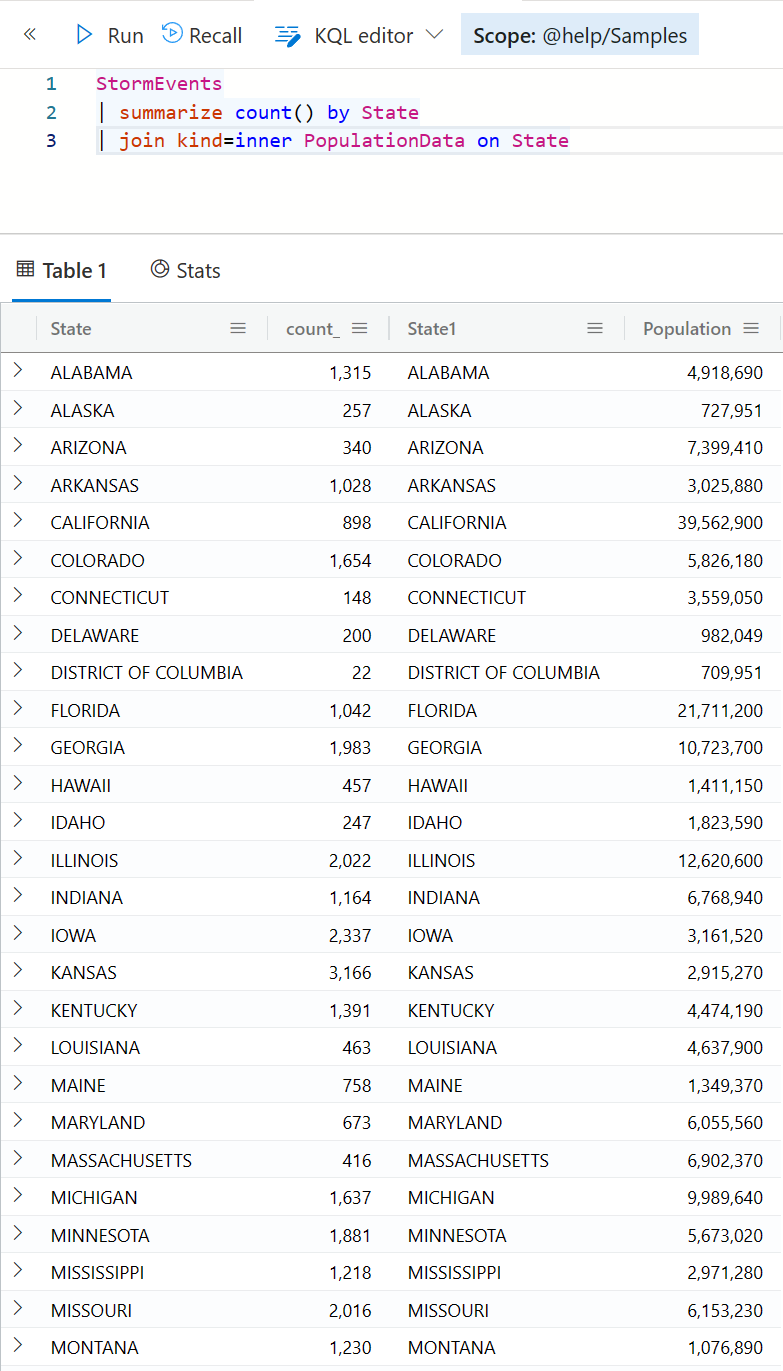
等一下,你已经看到,结果集会有四个列,而且第三个列是 State1,这是因为两个表都有 State 字段,所以第二个就会自动多一个数字的序号。如果想要拿掉这个列,你可以用此前介绍过的 project-away 操作符。
join (联接)支持多种方式,通过 kind 来定义,请参考下表的说明。

另外,在 on 子句后面,如果两个表都有同样的字段名,而且你就是想用这个字段来联接的话,可以直接 on 这个字段,而如果两个表的字段名是不同的,则可以用 $left 引用左表, $right 引用右表,并且指定要进行联接的具体字段名即可。
StormEvents
| summarize count() by State
| join kind=inner PopulationData on $left.State == $right.OtherColumn
| project-away OtherColumn
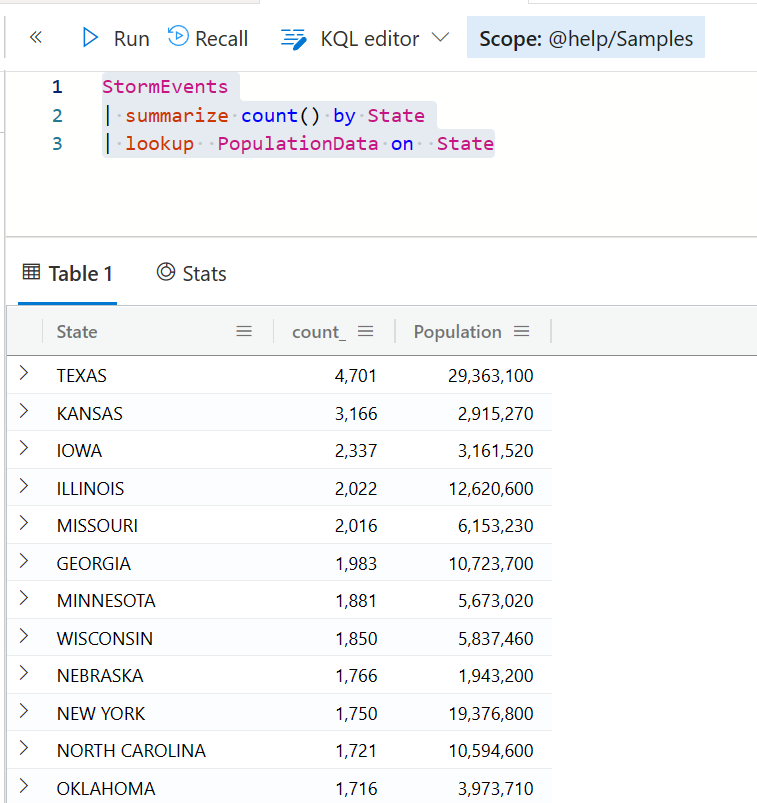
跟 join 很类似的一个操作符是 lookup ,上面的查询,我们也可以重写为下面这样。
StormEvents
| summarize count() by State
| lookup PopulationData on State
你会看到这个语法更简单,而且输出的结果集,也不会有重复的列,
那你可能会问,他们到底有啥区别呢?我的理解呢,lookup 是一个简化版的 join,首先它的 kind 只有两种, inner 和 leftouter , 另外你也看到了,它的语法和返回结果都更简单。
从性能角度来说,如果你用 join ,那么左表最好是更小的一个表。而如果你用 lookup,左表可以很大(通常是事实表),右表则需要小一些(通常是维度表)。
union
如果我们需要将多个结果集合并起来,不管是作为最终结果输出,还是作为数据源进一步进行加工,你都可以利用 union 这个操作符轻松完成。
本例请切换到 SampleLogs 这个范例数据库。
RawSysLogs
| union SecurityLogs
| take 100
如果你想在结果集中显示表的名字,可以添加 withsource 的设置,例如
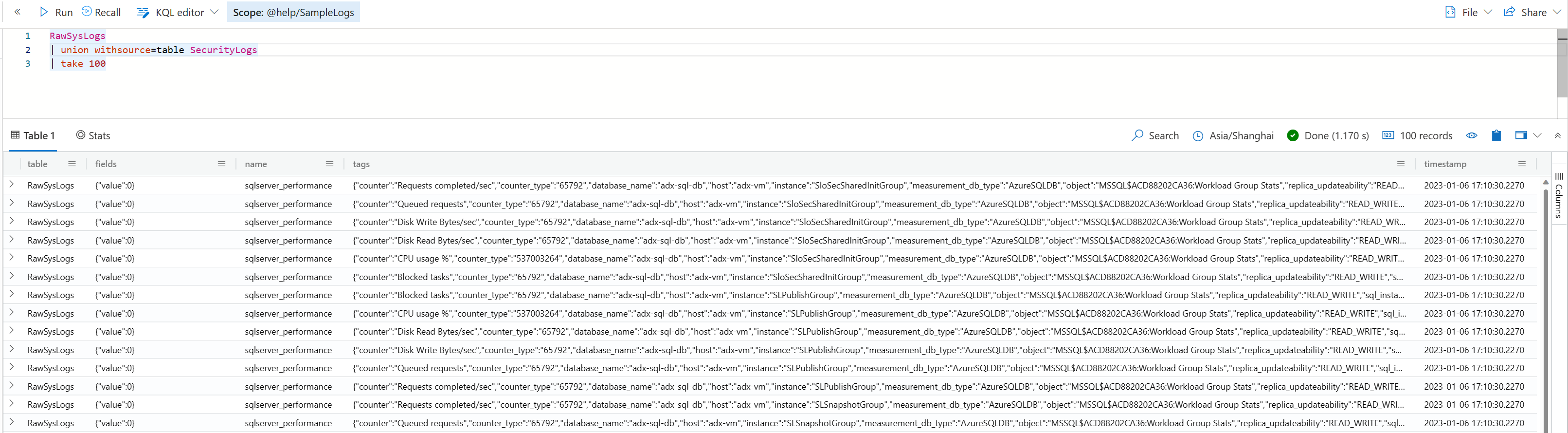
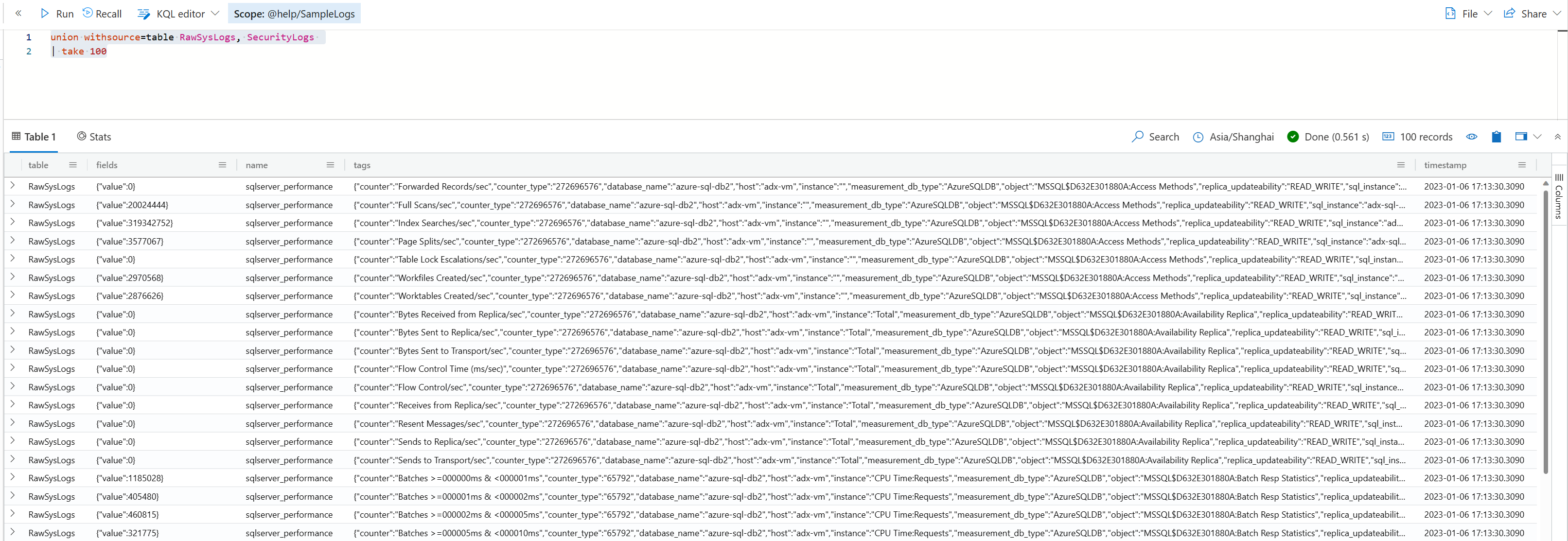
如果你希望把 union 的结果作为数据源,而不是最后的结果,则可以用下面这样的查询,将 union 作为顶级操作符使用。
union withsource=table RawSysLogs, SecurityLogs
| take 100
如果你的数据库中要好多名称很类似的表(或者视图),例如 sales2021, sales2022 这样的格式,而你需要一次性地把他们 union 起来,可以用 union sales* 这样的语法。
不要以为不会有这样的表(或视图),事实上这很常见。因为如果你的数据量真的很大,你可能会有这种需求,定期对数据进行预先聚合计算,然后单独存储起来,可以是一个表,也可以是一个物化视图。
多表查询的来源,可以是同一个数据库,也可以不同数据库,甚至不同的群集呢。下面这个查询,虽然实际意义不是很大,但你可以看到通过 cluster 函数可以访问到任意的群集, database 函数可以访问到任意的数据库,当然,前提是你当前的账号拥有必要的权限。
StormEvents
| top-nested 3 of State by sum(DamageCrops) + sum(DamageProperty),
top-nested 10 of EventType by count()
| union cluster('help').database('samples').StormEvents
| top-nested 3 of State by sum(DamageCrops) + sum(DamageProperty),
top-nested 10 of EventType by count()
当然,他们也可以不来自于数据库,请看下面的示例 ,第二个表的数据其实是我们硬编码在查询中的,这里用到了 datatable 这个操作符。
StormEvents
| top-nested 3 of State by sum(DamageCrops) + sum(DamageProperty),
top-nested 10 of EventType by count()
| union (datatable (
State: string,
aggregated_State: long,
EventType: string,
aggregated_EventType: long
) [
"CALIFORNIA", long(2801954600), "Heavy Snow", long(187),
"CALIFORNIA", long(2801954600), "High Wind", long(168),
"CALIFORNIA", long(2801954600), "Drought", long(78),
"CALIFORNIA", long(2801954600), "Frost/Freeze", long(71),
"CALIFORNIA", long(2801954600), "Wildfire", long(67),
"CALIFORNIA", long(2801954600), "Strong Wind", long(60),
"CALIFORNIA", long(2801954600), "Flash Flood", long(42),
"CALIFORNIA", long(2801954600), "Excessive Heat", long(37)
])
类似的还有 range 操作符,也可以用来生成一些有意思的数据,用到你的查询中。
StormEvents
| take 1000
| join kind=inner(
range x from datetime(2007-1-1) to datetime(2007-1-10) step 10m)
on $left.StartTime == $right.x
多个结果集
Kusto 的查询通常都只返回一个结果集,但利用 fork 和 facet 也可以实现一个查询输出多个结果集,下面的例子可以简单地管中窥豹。
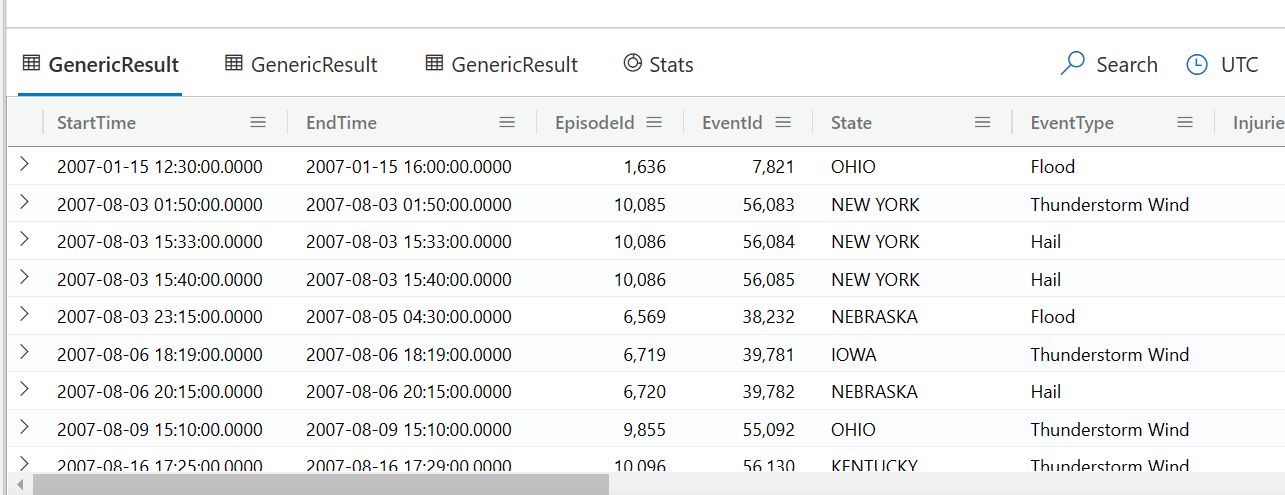
fork
fork 直接就是多个查询并行执行, 输出结果
StormEvents
| fork
(where StartTime >= datetime('2007-1-1') | take 100)
(summarize count() by State)
( project DamageCrops, DamageProperty | take 100 )
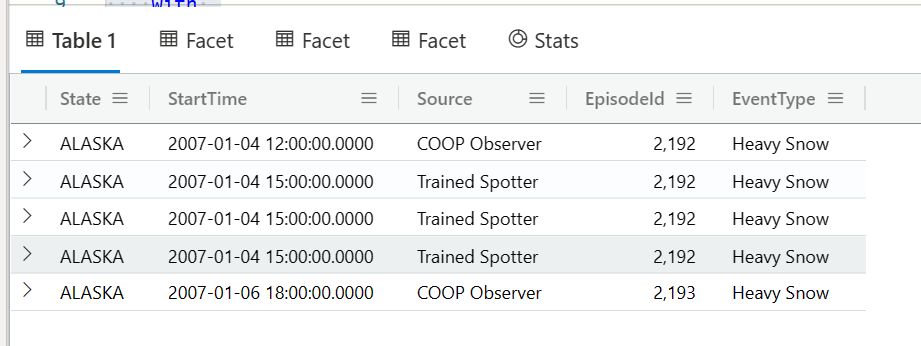
facet
facet 是根据几个字段(下例中的 State,EventType,Source,做一个计数,在前一句where的基础上)做一个基本统计, 并继续输出一个主要结果 (with后面的语句)
StormEvents
| where State startswith "A" and EventType has "Heavy"
| facet by State, EventType,Source
with
(
where StartTime between(datetime(2007-01-04) .. 7d)
| project State, StartTime, Source, EpisodeId, EventType
| take 5
)
Kusto 的查询学问很大,变化无穷。这一章涵盖的部分只是最基本的一些,希望大家已这个为起点,结合实际案例探索更多有意思的场景。以后我们可以再深入地研究和学习,尤其是针对典型的业务场景的分析案例,以及如何分析这些查询的性能,以便进行优化等等。